Module 5: Anomaly and Intrusion Detection with Machine Learning#
Why do we need anomaly detection in Cyber Security?#
Detecting and mitigating zero-day vulnerabilities is crucial for maintaining robust cybersecurity. A zero-day vulnerability represents a hidden weakness in a computer system, exploitable by attackers and undetected by affected parties. To comprehend the potential impact, consider the scenario where an organization falls victim to a zero-day exploit.
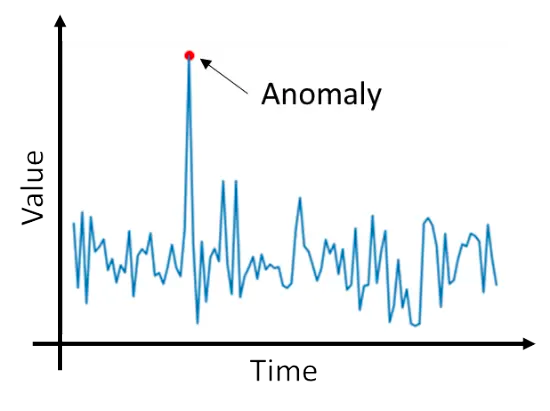
Identifying abnormal network behavior is instrumental in fortifying organizations against zero-day attacks. This document provides insights into various approaches to achieve effective anomaly detection.
Technical Explanation#
Anomaly detection, also known as outlier detection, involves recognizing unexpected events, observations, or items that significantly deviate from the norm. Anomalous data can often be easily identified by breaking established rules, such as exceeding predefined thresholds.
Properties of Anomaly
Anomalies in data occur infrequently.
Features of data anomalies are markedly different from those of normal instances.
Examples of Anomalies:
Network anomalies (e.g., intrusion detection forecasting)
Application performance anomalies
Web application security anomalies (e.g., XSS attacks, DDoS attacks, unexpected login attempts)
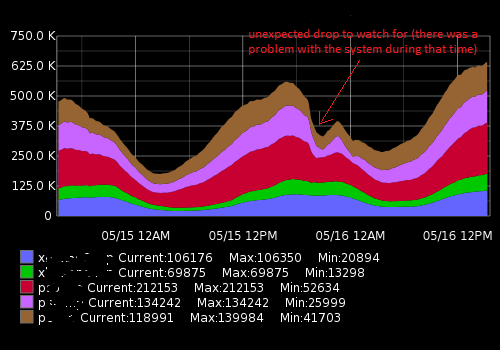
Refer below time series graph which shows unexpected drop in network usage (anomalous behaviour):
Challenges in Anomaly Detection:
Defining normal behavior
Handling imbalanced distribution of normal and abnormal data
Sparse occurrence of abnormal events
Appropriate feature extraction
Handling noise (distinct from anomalies)
Future anomalies may differ significantly from training set examples.
Testing for Anomalous Points:
Supervised training requires labeled anomalous data points.
Unsupervised learning relies on distances or cluster densities to estimate normalcy and outliers.
Feature Selection Criteria:
Choose features that exhibit unusually high or low values during anomaly events.
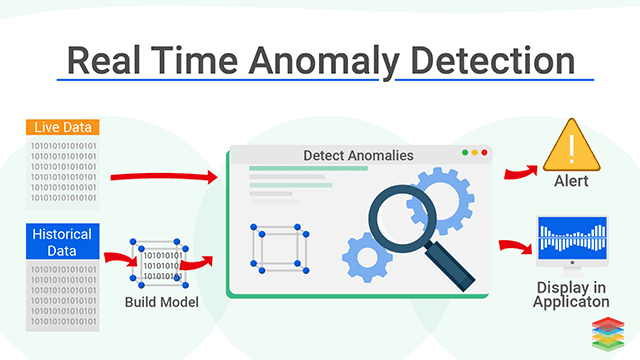
Real-Time Anomaly Detection#
In communication networks, real-time processing is vital for detecting correlated traffic indicative of anomalous behavior, such as DDoS or zero-day attacks.
Performance Evaluation Criteria: Given class imbalance, accuracy may not be a reliable metric. Confusion matrix analysis is recommended for a more nuanced evaluation.
Applications: Anomaly-based network intrusion detection system, credit card fraud detection, and malware detection are among the diverse applications. Practical examples and demonstrations, including a zero-day attack demo, are available in the provided resources.
In below picture, red points indicates anomaly based on previously seen data points.

Noise Filtering: Prior to applying anomaly detection techniques, noise filtering is essential to reduce false positives. A recommended approach is discussed in the referenced paper.
Case Study: Detecting Intrusion with Machine Learning#
Training data: “Intrusion Detection Evaluation Dataset” (CICIDS2017). Description page: https://www.unb.ca/cic/datasets/ids-2017.html
The data set is public. Download link: http://205.174.165.80/CICDataset/CIC-IDS-2017/Dataset/
CICIDS2017 combines 8 files recorded on different days of observation (PCAP + CSV). Used archive: http://205.174.165.80/CICDataset/CIC-IDS-2017/Dataset/GeneratedLabelledFlows.zip
In the downloaded archive GeneratedLabelledFlows.zip the file “Thursday” Thursday-WorkingHours-Morning-WebAttacks.pcap_ISCX.csv is selected.
Sources:
[Sharafaldin2018] Iman Sharafaldin, Arash Habibi Lashkari and Ali A. Ghorbani. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. 2018
[Kostas2018] Kahraman Kostas. Anomaly Detection in Networks Using Machine Learning. 2018 (error was found in assessing the importance of features)
bozbil/Anomaly-Detection-in-Networks-Using-Machine-Learning (error was found in assessing the importance of features)
Data preprocessing#
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
from IPython.display import display
%matplotlib inline
Download the dataset from Github to Google Colab and unzip it.
!pip install graphviz
Requirement already satisfied: graphviz in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (0.20.1)
We use “engine=python” to avoid the “UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x96 in position 11: invalid start byte” encoding error.
df = pd.read_csv(
"https://raw.githubusercontent.com/WSU-AI-CyberSecurity/data/master/CICIDS2017-thursday.pcap_ISCX.csv",
encoding="cp1252",
low_memory=False,
)
df
| Flow ID | Source IP | Source Port | Destination IP | Destination Port | Protocol | Timestamp | Flow Duration | Total Fwd Packets | Total Backward Packets | ... | min_seg_size_forward | Active Mean | Active Std | Active Max | Active Min | Idle Mean | Idle Std | Idle Max | Idle Min | Label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 192.168.10.3-192.168.10.50-389-33898-6 | 192.168.10.50 | 33898 | 192.168.10.3 | 389 | 6 | 6/7/2017 8:59 | 113095465 | 48 | 24 | ... | 32 | 203985.500 | 5.758373e+05 | 1629110.0 | 379.0 | 13800000.0 | 4.277541e+06 | 16500000.0 | 6737603.0 | BENIGN |
| 1 | 192.168.10.3-192.168.10.50-389-33904-6 | 192.168.10.50 | 33904 | 192.168.10.3 | 389 | 6 | 6/7/2017 8:59 | 113473706 | 68 | 40 | ... | 32 | 178326.875 | 5.034269e+05 | 1424245.0 | 325.0 | 13800000.0 | 4.229413e+06 | 16500000.0 | 6945512.0 | BENIGN |
| 2 | 8.0.6.4-8.6.0.1-0-0-0 | 8.6.0.1 | 0 | 8.0.6.4 | 0 | 0 | 6/7/2017 8:59 | 119945515 | 150 | 0 | ... | 0 | 6909777.333 | 1.170000e+07 | 20400000.0 | 6.0 | 24400000.0 | 2.430000e+07 | 60100000.0 | 5702188.0 | BENIGN |
| 3 | 192.168.10.14-65.55.44.109-59135-443-6 | 192.168.10.14 | 59135 | 65.55.44.109 | 443 | 6 | 6/7/2017 8:59 | 60261928 | 9 | 7 | ... | 20 | 0.000 | 0.000000e+00 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 0.0 | 0.0 | BENIGN |
| 4 | 192.168.10.3-192.168.10.14-53-59555-17 | 192.168.10.14 | 59555 | 192.168.10.3 | 53 | 17 | 6/7/2017 8:59 | 269 | 2 | 2 | ... | 32 | 0.000 | 0.000000e+00 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 0.0 | 0.0 | BENIGN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 170361 | 157.240.18.35-192.168.10.51-443-55641-6 | 157.240.18.35 | 443 | 192.168.10.51 | 55641 | 6 | 6/7/2017 12:59 | 49 | 1 | 3 | ... | 20 | 0.000 | 0.000000e+00 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 0.0 | 0.0 | BENIGN |
| 170362 | 192.168.10.51-199.16.156.120-45337-443-6 | 199.16.156.120 | 443 | 192.168.10.51 | 45337 | 6 | 6/7/2017 12:59 | 217 | 2 | 1 | ... | 32 | 0.000 | 0.000000e+00 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 0.0 | 0.0 | BENIGN |
| 170363 | 192.168.10.12-192.168.10.50-60148-22-6 | 192.168.10.12 | 60148 | 192.168.10.50 | 22 | 6 | 6/7/2017 12:59 | 1387547 | 41 | 46 | ... | 32 | 0.000 | 0.000000e+00 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 0.0 | 0.0 | BENIGN |
| 170364 | 192.168.10.12-192.168.10.50-60146-22-6 | 192.168.10.12 | 60146 | 192.168.10.50 | 22 | 6 | 6/7/2017 12:59 | 207 | 1 | 1 | ... | 32 | 0.000 | 0.000000e+00 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 0.0 | 0.0 | BENIGN |
| 170365 | 192.168.10.12-192.168.10.50-60146-22-6 | 192.168.10.50 | 22 | 192.168.10.12 | 60146 | 6 | 6/7/2017 12:59 | 50 | 1 | 2 | ... | 32 | 0.000 | 0.000000e+00 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 0.0 | 0.0 | BENIGN |
170366 rows × 85 columns
df.shape
(170366, 85)
The columns “Fwd Header Length” and “Fwd Header Length.1” are identical, the second one is removed, 84 columns remain.
df.columns = df.columns.str.strip()
df = df.drop(columns=["Fwd Header Length.1"])
df.shape
(170366, 84)
When assessing the distribution of labels, it turns out that out of 458968 records there are many blank records (“BENIGN” - benign background traffic).
df["Label"].unique()
array(['BENIGN', 'Web Attack – Brute Force', 'Web Attack – XSS',
'Web Attack – Sql Injection'], dtype=object)
df["Label"].value_counts()
Label
BENIGN 168186
Web Attack – Brute Force 1507
Web Attack – XSS 652
Web Attack – Sql Injection 21
Name: count, dtype: int64
Delete blank records.
df = df.drop(df[pd.isnull(df["Flow ID"])].index)
df.shape
(170366, 84)
The “Flow Bytes/s” and “Flow Packets/s” columns have non-numerical values, replace them.
df.replace("Infinity", -1, inplace=True)
df[["Flow Bytes/s", "Flow Packets/s"]] = df[["Flow Bytes/s", "Flow Packets/s"]].apply(
pd.to_numeric
)
Replace the NaN values and infinity values with -1.
df.replace([np.inf, -np.inf, np.nan], -1, inplace=True)
Convert string characters to numbers, use LabelEncoder, not OneHotEncoder.
string_features = list(df.select_dtypes(include=["object"]).columns)
string_features.remove("Label")
string_features
['Flow ID', 'Source IP', 'Destination IP', 'Timestamp']
le = preprocessing.LabelEncoder()
df[string_features] = df[string_features].apply(lambda col: le.fit_transform(col))
Undersampling against unbalance#
Dataset is unbalanced: total records = 170366, “BENIGN” records = 168186, records with attacks much less: 1507 + 652 + 21 = 2180.
benign_total = len(df[df["Label"] == "BENIGN"])
benign_total
168186
attack_total = len(df[df["Label"] != "BENIGN"])
attack_total
2180
df.to_csv("web_attacks_unbalanced.csv", index=False)
df["Label"].value_counts()
Label
BENIGN 168186
Web Attack – Brute Force 1507
Web Attack – XSS 652
Web Attack – Sql Injection 21
Name: count, dtype: int64
We use undersampling to correct class imbalances: we remove most of the “BENIGN” records.
Form a balanced dataset web_attacks_balanced.csv in proportion: 30% attack (2180 records), 70% benign data (2180 / 30 * 70 ~ = 5087 records).
Algorithm to form a balanced df_balanced dataset:
All the records with the attacks are copied to the new dataset.
There are two conditions for copying “BENIGN” records to the new dataset:
The next record is copyied with the benign_inc_probability.
The total number of “BENIGN” records must not exceed the limit of 5087 records.
Сalculate the probability of copying a “BENIGN” record. The enlargement multiplier is used to get exactly 70% benign data (5087 records).
enlargement = 1.1
benign_included_max = attack_total / 30 * 70
benign_inc_probability = (benign_included_max / benign_total) * enlargement
print(benign_included_max, benign_inc_probability)
5086.666666666667 0.03326872232726466
Copy records from df to df_balanced, save dataset web_attacks_balanced.csv.
import random
indexes = []
benign_included_count = 0
for index, row in df.iterrows():
if row["Label"] != "BENIGN":
indexes.append(index)
else:
# Copying with benign_inc_probability
if random.random() > benign_inc_probability:
continue
# Have we achieved 70% (5087 records)?
if benign_included_count > benign_included_max:
continue
benign_included_count += 1
indexes.append(index)
df_balanced = df.loc[indexes]
df_balanced["Label"].value_counts()
Label
BENIGN 5087
Web Attack – Brute Force 1507
Web Attack – XSS 652
Web Attack – Sql Injection 21
Name: count, dtype: int64
Preparing data for training#
df = df_balanced.copy()
The Label column is encoded as follows: “BENIGN” = 0, attack = 1.
df["Label"] = df["Label"].apply(lambda x: 0 if x == "BENIGN" else 1)
7 features (Flow ID, Source IP, Source Port, Destination IP, Destination Port, Protocol, Timestamp) are excluded from the dataset. The hypothesis is that the “shape” of the data being transmitted is more important than these attributes. In addition, ports and addresses can be substituted by an attacker, so it is better that the ML algorithm does not take these features into account in training [Kostas2018].
excluded = [
"Flow ID",
"Source IP",
"Source Port",
"Destination IP",
"Destination Port",
"Protocol",
"Timestamp",
]
df = df.drop(columns=excluded, errors="ignore")
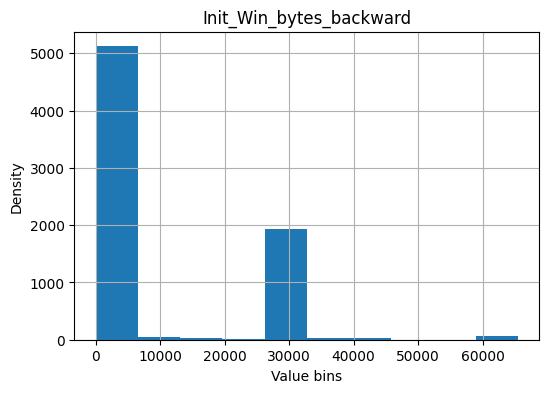
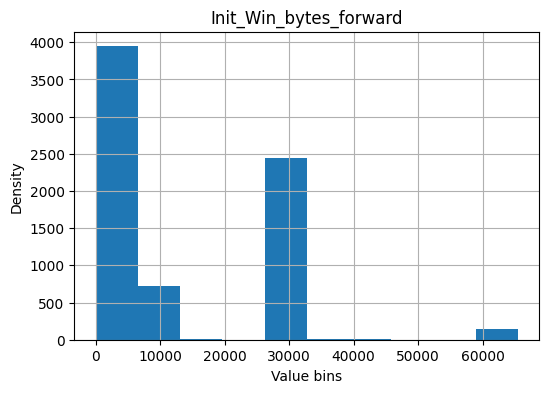
Below at the stage of importance estimation the “Init_Win_bytes_backward” feature has the maximum value. After viewing the source dataset, it seems that an inaccuracy was made in forming the dataset.
It turns out that it is possible to make a fairly accurate classification by one feature.
Description of features: http://www.netflowmeter.ca/netflowmeter.html
Init_Win_bytes_backward - The total number of bytes sent in initial window in the backward direction
Init_Win_bytes_forward - The total number of bytes sent in initial window in the forward direction
if "Init_Win_bytes_backward" in df.columns:
df["Init_Win_bytes_backward"].hist(figsize=(6, 4), bins=10)
plt.title("Init_Win_bytes_backward")
plt.xlabel("Value bins")
plt.ylabel("Density")
plt.savefig("Init_Win_bytes_backward.png", dpi=300)
if "Init_Win_bytes_forward" in df.columns:
df["Init_Win_bytes_forward"].hist(figsize=(6, 4), bins=10)
plt.title("Init_Win_bytes_forward")
plt.xlabel("Value bins")
plt.ylabel("Density")
plt.savefig("Init_Win_bytes_forward.png", dpi=300)
excluded2 = ["Init_Win_bytes_backward", "Init_Win_bytes_forward"]
df = df.drop(columns=excluded2, errors="ignore")
y = df["Label"].values
X = df.drop(columns=["Label"])
print(X.shape, y.shape)
(7267, 74) (7267,)
Feature importance#
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
unique, counts = np.unique(y_train, return_counts=True)
dict(zip(unique, counts))
{0: 3571, 1: 1515}
Visualization of the decision tree, importance evaluation using a single tree (DecisionTreeClassifier)#
In the beginning we use one tree - for the convenience of visualization of the classifier. High cross-validation scores even with 5 leaves look suspiciously good, we should look at the data carefully. Parameters for change - test_size in the cell above (train_test_split), max_leaf_nodes in the cell below.
By changing the random_state parameter, we will get different trees and different features with the highest importance. But the forest will already average individual trees below.
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
decision_tree = DecisionTreeClassifier(max_leaf_nodes=5, random_state=0)
decision_tree = decision_tree.fit(X_train, y_train)
cross_val_score(decision_tree, X_train, y_train, cv=10)
array([0.96463654, 0.95284872, 0.95874263, 0.97249509, 0.95284872,
0.94695481, 0.94685039, 0.97244094, 0.96259843, 0.96259843])
from sklearn.tree import export_text
r = export_text(decision_tree, feature_names=X_train.columns.to_list())
print(r)
|--- Max Packet Length <= 3.00
| |--- Fwd IAT Std <= 2454249.88
| | |--- Bwd Packets/s <= 10256.68
| | | |--- class: 0
| | |--- Bwd Packets/s > 10256.68
| | | |--- class: 0
| |--- Fwd IAT Std > 2454249.88
| | |--- class: 1
|--- Max Packet Length > 3.00
| |--- Total Length of Fwd Packets <= 32821.50
| | |--- class: 0
| |--- Total Length of Fwd Packets > 32821.50
| | |--- class: 1
from graphviz import Source
from sklearn import tree
Source(tree.export_graphviz(decision_tree, out_file=None, feature_names=X.columns))
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/graphviz/backend/execute.py:79, in run_check(cmd, input_lines, encoding, quiet, **kwargs)
78 kwargs['stdout'] = kwargs['stderr'] = subprocess.PIPE
---> 79 proc = _run_input_lines(cmd, input_lines, kwargs=kwargs)
80 else:
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/graphviz/backend/execute.py:99, in _run_input_lines(cmd, input_lines, kwargs)
98 def _run_input_lines(cmd, input_lines, *, kwargs):
---> 99 popen = subprocess.Popen(cmd, stdin=subprocess.PIPE, **kwargs)
101 stdin_write = popen.stdin.write
File ~/micromamba/envs/wsu/lib/python3.9/subprocess.py:951, in Popen.__init__(self, args, bufsize, executable, stdin, stdout, stderr, preexec_fn, close_fds, shell, cwd, env, universal_newlines, startupinfo, creationflags, restore_signals, start_new_session, pass_fds, user, group, extra_groups, encoding, errors, text, umask)
948 self.stderr = io.TextIOWrapper(self.stderr,
949 encoding=encoding, errors=errors)
--> 951 self._execute_child(args, executable, preexec_fn, close_fds,
952 pass_fds, cwd, env,
953 startupinfo, creationflags, shell,
954 p2cread, p2cwrite,
955 c2pread, c2pwrite,
956 errread, errwrite,
957 restore_signals,
958 gid, gids, uid, umask,
959 start_new_session)
960 except:
961 # Cleanup if the child failed starting.
File ~/micromamba/envs/wsu/lib/python3.9/subprocess.py:1837, in Popen._execute_child(self, args, executable, preexec_fn, close_fds, pass_fds, cwd, env, startupinfo, creationflags, shell, p2cread, p2cwrite, c2pread, c2pwrite, errread, errwrite, restore_signals, gid, gids, uid, umask, start_new_session)
1836 err_msg = os.strerror(errno_num)
-> 1837 raise child_exception_type(errno_num, err_msg, err_filename)
1838 raise child_exception_type(err_msg)
FileNotFoundError: [Errno 2] No such file or directory: PosixPath('dot')
The above exception was the direct cause of the following exception:
ExecutableNotFound Traceback (most recent call last)
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/IPython/core/formatters.py:974, in MimeBundleFormatter.__call__(self, obj, include, exclude)
971 method = get_real_method(obj, self.print_method)
973 if method is not None:
--> 974 return method(include=include, exclude=exclude)
975 return None
976 else:
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/graphviz/jupyter_integration.py:98, in JupyterIntegration._repr_mimebundle_(self, include, exclude, **_)
96 include = set(include) if include is not None else {self._jupyter_mimetype}
97 include -= set(exclude or [])
---> 98 return {mimetype: getattr(self, method_name)()
99 for mimetype, method_name in MIME_TYPES.items()
100 if mimetype in include}
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/graphviz/jupyter_integration.py:98, in <dictcomp>(.0)
96 include = set(include) if include is not None else {self._jupyter_mimetype}
97 include -= set(exclude or [])
---> 98 return {mimetype: getattr(self, method_name)()
99 for mimetype, method_name in MIME_TYPES.items()
100 if mimetype in include}
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/graphviz/jupyter_integration.py:112, in JupyterIntegration._repr_image_svg_xml(self)
110 def _repr_image_svg_xml(self) -> str:
111 """Return the rendered graph as SVG string."""
--> 112 return self.pipe(format='svg', encoding=SVG_ENCODING)
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/graphviz/piping.py:104, in Pipe.pipe(self, format, renderer, formatter, neato_no_op, quiet, engine, encoding)
55 def pipe(self,
56 format: typing.Optional[str] = None,
57 renderer: typing.Optional[str] = None,
(...)
61 engine: typing.Optional[str] = None,
62 encoding: typing.Optional[str] = None) -> typing.Union[bytes, str]:
63 """Return the source piped through the Graphviz layout command.
64
65 Args:
(...)
102 '<?xml version='
103 """
--> 104 return self._pipe_legacy(format,
105 renderer=renderer,
106 formatter=formatter,
107 neato_no_op=neato_no_op,
108 quiet=quiet,
109 engine=engine,
110 encoding=encoding)
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/graphviz/_tools.py:171, in deprecate_positional_args.<locals>.decorator.<locals>.wrapper(*args, **kwargs)
162 wanted = ', '.join(f'{name}={value!r}'
163 for name, value in deprecated.items())
164 warnings.warn(f'The signature of {func.__name__} will be reduced'
165 f' to {supported_number} positional args'
166 f' {list(supported)}: pass {wanted}'
167 ' as keyword arg(s)',
168 stacklevel=stacklevel,
169 category=category)
--> 171 return func(*args, **kwargs)
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/graphviz/piping.py:121, in Pipe._pipe_legacy(self, format, renderer, formatter, neato_no_op, quiet, engine, encoding)
112 @_tools.deprecate_positional_args(supported_number=2)
113 def _pipe_legacy(self,
114 format: typing.Optional[str] = None,
(...)
119 engine: typing.Optional[str] = None,
120 encoding: typing.Optional[str] = None) -> typing.Union[bytes, str]:
--> 121 return self._pipe_future(format,
122 renderer=renderer,
123 formatter=formatter,
124 neato_no_op=neato_no_op,
125 quiet=quiet,
126 engine=engine,
127 encoding=encoding)
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/graphviz/piping.py:149, in Pipe._pipe_future(self, format, renderer, formatter, neato_no_op, quiet, engine, encoding)
146 if encoding is not None:
147 if codecs.lookup(encoding) is codecs.lookup(self.encoding):
148 # common case: both stdin and stdout need the same encoding
--> 149 return self._pipe_lines_string(*args, encoding=encoding, **kwargs)
150 try:
151 raw = self._pipe_lines(*args, input_encoding=self.encoding, **kwargs)
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/graphviz/backend/piping.py:212, in pipe_lines_string(engine, format, input_lines, encoding, renderer, formatter, neato_no_op, quiet)
206 cmd = dot_command.command(engine, format,
207 renderer=renderer,
208 formatter=formatter,
209 neato_no_op=neato_no_op)
210 kwargs = {'input_lines': input_lines, 'encoding': encoding}
--> 212 proc = execute.run_check(cmd, capture_output=True, quiet=quiet, **kwargs)
213 return proc.stdout
File ~/micromamba/envs/wsu/lib/python3.9/site-packages/graphviz/backend/execute.py:84, in run_check(cmd, input_lines, encoding, quiet, **kwargs)
82 except OSError as e:
83 if e.errno == errno.ENOENT:
---> 84 raise ExecutableNotFound(cmd) from e
85 raise
87 if not quiet and proc.stderr:
ExecutableNotFound: failed to execute PosixPath('dot'), make sure the Graphviz executables are on your systems' PATH
<graphviz.sources.Source at 0x7f28caed4d30>
Analyze the confusion matrix. Which classes are confidently classified by the model?
unique, counts = np.unique(y_test, return_counts=True)
dict(zip(unique, counts))
{0: 1516, 1: 665}
from sklearn.metrics import confusion_matrix
y_pred = decision_tree.predict(X_test)
confusion_matrix(y_test, y_pred)
array([[1505, 11],
[ 97, 568]])
Importance evaluation using SelectFromModel#
from sklearn.feature_selection import SelectFromModel
sfm = SelectFromModel(estimator=decision_tree).fit(X_train, y_train)
sfm.estimator_.feature_importances_
array([0. , 0. , 0. , 0.06230676, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.1981437 , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.01768306, 0. , 0.72186648, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. ])
sfm.threshold_
0.013513513513513514
X_train_new = sfm.transform(X_train)
print(
"Original num features: {}, selected num features: {}".format(
X_train.shape[1], X_train_new.shape[1]
)
)
Original num features: 74, selected num features: 4
indices = np.argsort(decision_tree.feature_importances_)[::-1]
for idx, i in enumerate(indices[:10]):
print(
"{}.\t{} - {}".format(
idx, X_train.columns[i], decision_tree.feature_importances_[i]
)
)
0. Max Packet Length - 0.7218664752320741
1. Fwd IAT Std - 0.19814370190487834
2. Total Length of Fwd Packets - 0.06230675880412216
3. Bwd Packets/s - 0.017683064058925304
4. Bwd IAT Std - 0.0
5. Fwd IAT Mean - 0.0
6. Fwd IAT Max - 0.0
7. Fwd IAT Min - 0.0
8. Bwd IAT Total - 0.0
9. Bwd IAT Mean - 0.0
Evaluation of importance using RandomForestClassifier.feature_importances_#
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=250, random_state=42, oob_score=True)
rf.fit(X_train, y_train)
# Score = mean accuracy on the given test data and labels
print(
"R^2 Training Score: {:.2f} \nR^2 Validation Score: {:.2f} \nOut-of-bag Score: {:.2f}".format(
rf.score(X_train, y_train), rf.score(X_test, y_test), rf.oob_score_
)
)
R^2 Training Score: 0.99
R^2 Validation Score: 0.97
Out-of-bag Score: 0.98
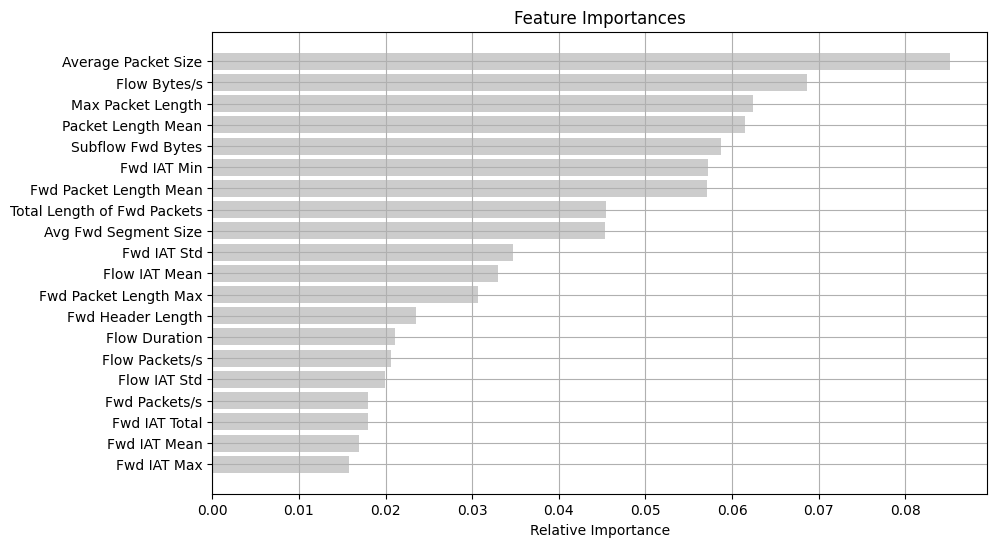
features = X.columns
importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]
webattack_features = []
for index, i in enumerate(indices[:20]):
webattack_features.append(features[i])
print("{}.\t#{}\t{:.3f}\t{}".format(index + 1, i, importances[i], features[i]))
1. #51 0.085 Average Packet Size
2. #13 0.069 Flow Bytes/s
3. #38 0.062 Max Packet Length
4. #39 0.062 Packet Length Mean
5. #61 0.059 Subflow Fwd Bytes
6. #23 0.057 Fwd IAT Min
7. #7 0.057 Fwd Packet Length Mean
8. #3 0.045 Total Length of Fwd Packets
9. #52 0.045 Avg Fwd Segment Size
10. #21 0.035 Fwd IAT Std
11. #15 0.033 Flow IAT Mean
12. #5 0.031 Fwd Packet Length Max
13. #33 0.024 Fwd Header Length
14. #0 0.021 Flow Duration
15. #14 0.021 Flow Packets/s
16. #16 0.020 Flow IAT Std
17. #35 0.018 Fwd Packets/s
18. #19 0.018 Fwd IAT Total
19. #20 0.017 Fwd IAT Mean
20. #22 0.016 Fwd IAT Max
For comparison, the results of the study [Sharafaldin2018] (compare relatively, without taking into account the multiplier):
Init Win F.Bytes 0.0200
Subflow F.Bytes 0.0145
Init Win B.Bytes 0.0129
Total Len F.Packets 0.0096
And incorrect results [Kostas2018] (error was found in assessing the importance of features, line: impor_bars = pd.DataFrame({‘Features’:refclasscol[0:20],’importance’:importances[0:20]}), the importances[0:20] sample does not take into account that the values are not sorted in descending order):
Flow Bytes/s 0.313402
Total Length of Fwd Packets 0.304917
Flow Duration 0.000485
Fwd Packet Length Max 0.00013
indices = np.argsort(importances)[-20:]
plt.rcParams["figure.figsize"] = (10, 6)
plt.title("Feature Importances")
plt.barh(range(len(indices)), importances[indices], color="#cccccc", align="center")
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel("Relative Importance")
plt.grid()
plt.savefig("feature_importances.png", dpi=300, bbox_inches="tight")
plt.show()
y_pred = rf.predict(X_test)
confusion_matrix(y_test, y_pred)
array([[1495, 21],
[ 34, 631]])
Next, for experiments, we keep the first max_features of features with maximum importance.
max_features = 20
webattack_features = webattack_features[:max_features]
webattack_features
['Average Packet Size',
'Flow Bytes/s',
'Max Packet Length',
'Packet Length Mean',
'Subflow Fwd Bytes',
'Fwd IAT Min',
'Fwd Packet Length Mean',
'Total Length of Fwd Packets',
'Avg Fwd Segment Size',
'Fwd IAT Std',
'Flow IAT Mean',
'Fwd Packet Length Max',
'Fwd Header Length',
'Flow Duration',
'Flow Packets/s',
'Flow IAT Std',
'Fwd Packets/s',
'Fwd IAT Total',
'Fwd IAT Mean',
'Fwd IAT Max']
Analysis of selected features#
df[webattack_features].hist(figsize=(20, 12), bins=10)
plt.savefig("features_hist.png", dpi=300)
Install Facets Overview
https://pair-code.github.io/facets/
!pip install facets-overview
Requirement already satisfied: facets-overview in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (1.1.1)
Requirement already satisfied: numpy>=1.16.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from facets-overview) (1.26.3)
Requirement already satisfied: pandas>=0.22.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from facets-overview) (2.2.0)
Requirement already satisfied: protobuf>=3.20.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from facets-overview) (4.23.4)
Requirement already satisfied: python-dateutil>=2.8.2 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from pandas>=0.22.0->facets-overview) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from pandas>=0.22.0->facets-overview) (2024.1)
Requirement already satisfied: tzdata>=2022.7 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from pandas>=0.22.0->facets-overview) (2023.4)
Requirement already satisfied: six>=1.5 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from python-dateutil>=2.8.2->pandas>=0.22.0->facets-overview) (1.16.0)
Create the feature stats for the datasets and stringify it.
import base64
from facets_overview.generic_feature_statistics_generator import (
GenericFeatureStatisticsGenerator,
)
gfsg = GenericFeatureStatisticsGenerator()
proto = gfsg.ProtoFromDataFrames(
[{"name": "train + test", "table": df[webattack_features]}]
)
protostr = base64.b64encode(proto.SerializeToString()).decode("utf-8")
/home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages/facets_overview/base_generic_feature_statistics_generator.py:121: FutureWarning: Series.ravel is deprecated. The underlying array is already 1D, so ravel is not necessary. Use `to_numpy()` for conversion to a numpy array instead.
flattened = x.ravel()
Display the facets overview visualization for this data.
from IPython.display import display, HTML
HTML_TEMPLATE = """
<script src="https://cdnjs.cloudflare.com/ajax/libs/webcomponentsjs/1.3.3/webcomponents-lite.js"></script>
<link rel="import" href="https://raw.githubusercontent.com/PAIR-code/facets/1.0.0/facets-dist/facets-jupyter.html" >
<facets-overview id="elem"></facets-overview>
<script>
document.querySelector("#elem").protoInput = "{protostr}";
</script>"""
html = HTML_TEMPLATE.format(protostr=protostr)
display(HTML(html))
import seaborn as sns
corr_matrix = df[webattack_features].corr()
plt.rcParams["figure.figsize"] = (16, 5)
g = sns.heatmap(corr_matrix, annot=True, fmt=".1g", cmap="Greys")
g.set_xticklabels(
g.get_xticklabels(),
verticalalignment="top",
horizontalalignment="right",
rotation=30,
)
plt.savefig("corr_heatmap.png", dpi=300, bbox_inches="tight")
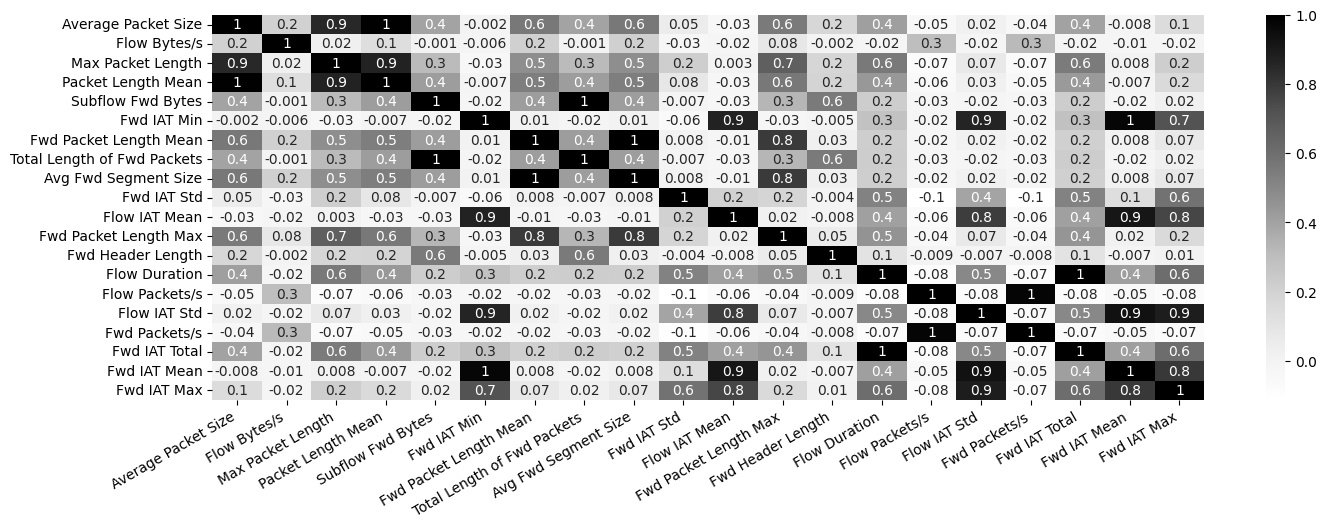
Remove correlated features.
to_be_removed = {
"Packet Length Mean",
"Avg Fwd Segment Size",
"Subflow Fwd Bytes",
"Fwd Packets/s",
"Fwd IAT Total",
"Fwd IAT Max",
}
webattack_features = [item for item in webattack_features if item not in to_be_removed]
webattack_features = webattack_features[:10]
webattack_features
['Average Packet Size',
'Flow Bytes/s',
'Max Packet Length',
'Fwd IAT Min',
'Fwd Packet Length Mean',
'Total Length of Fwd Packets',
'Fwd IAT Std',
'Flow IAT Mean',
'Fwd Packet Length Max',
'Fwd Header Length']
corr_matrix = df[webattack_features].corr()
plt.rcParams["figure.figsize"] = (6, 5)
sns.heatmap(corr_matrix, annot=True, fmt=".1g", cmap="Greys");
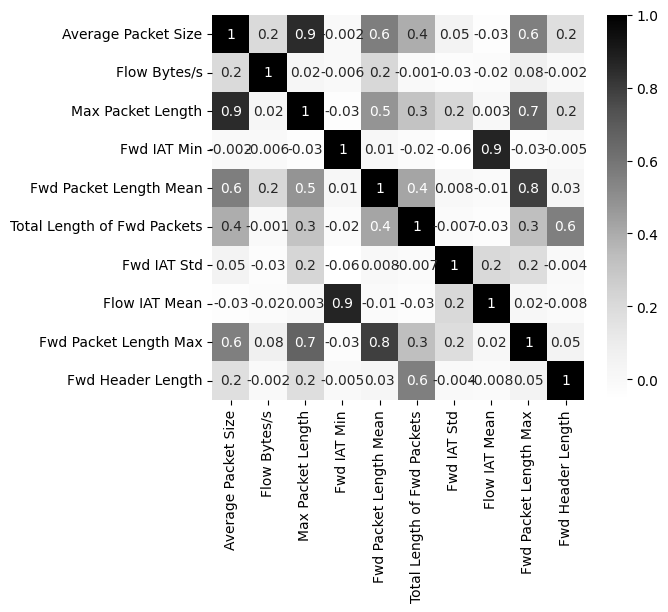
Hyperparameter selection#
Reopen the dataset.
from sklearn.model_selection import GridSearchCV
df = df_balanced.copy()
df["Label"] = df["Label"].apply(lambda x: 0 if x == "BENIGN" else 1)
y = df["Label"].values
X = df[webattack_features]
print(X.shape, y.shape)
(7267, 10) (7267,)
We get the list of RandomForestClassifier parameters.
rfc = RandomForestClassifier(random_state=1)
rfc.get_params().keys()
dict_keys(['bootstrap', 'ccp_alpha', 'class_weight', 'criterion', 'max_depth', 'max_features', 'max_leaf_nodes', 'max_samples', 'min_impurity_decrease', 'min_samples_leaf', 'min_samples_split', 'min_weight_fraction_leaf', 'monotonic_cst', 'n_estimators', 'n_jobs', 'oob_score', 'random_state', 'verbose', 'warm_start'])
For search of quasi-optimal value of one parameter we fix the others.
parameters = {
"n_estimators": [10],
"min_samples_leaf": [3],
"max_features": [3],
"max_depth": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 15, 17, 20, 30, 50],
}
scoring = ("f1", "accuracy")
gcv = GridSearchCV(
rfc, parameters, scoring=scoring, refit="f1", cv=10, return_train_score=True
)
gcv.fit(X, y)
results = gcv.cv_results_
cv_results = pd.DataFrame(gcv.cv_results_)
cv_results.head()
| mean_fit_time | std_fit_time | mean_score_time | std_score_time | param_max_depth | param_max_features | param_min_samples_leaf | param_n_estimators | params | split0_test_f1 | ... | split2_train_accuracy | split3_train_accuracy | split4_train_accuracy | split5_train_accuracy | split6_train_accuracy | split7_train_accuracy | split8_train_accuracy | split9_train_accuracy | mean_train_accuracy | std_train_accuracy | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.011794 | 0.000374 | 0.001573 | 0.000136 | 1 | 3 | 3 | 10 | {'max_depth': 1, 'max_features': 3, 'min_sampl... | 0.891509 | ... | 0.906575 | 0.906881 | 0.905505 | 0.909786 | 0.905199 | 0.906131 | 0.904908 | 0.908730 | 0.906564 | 0.001923 |
| 1 | 0.015826 | 0.000166 | 0.001633 | 0.000103 | 2 | 3 | 3 | 10 | {'max_depth': 2, 'max_features': 3, 'min_sampl... | 0.894472 | ... | 0.959021 | 0.958257 | 0.958410 | 0.958257 | 0.959633 | 0.955359 | 0.954900 | 0.959792 | 0.958182 | 0.001711 |
| 2 | 0.019654 | 0.000284 | 0.001686 | 0.000130 | 3 | 3 | 3 | 10 | {'max_depth': 3, 'max_features': 3, 'min_sampl... | 0.891688 | ... | 0.959174 | 0.958410 | 0.958716 | 0.959174 | 0.959480 | 0.955053 | 0.955206 | 0.959945 | 0.958396 | 0.001723 |
| 3 | 0.022836 | 0.000558 | 0.001778 | 0.000117 | 4 | 3 | 3 | 10 | {'max_depth': 4, 'max_features': 3, 'min_sampl... | 0.916256 | ... | 0.972018 | 0.967125 | 0.966667 | 0.962691 | 0.969572 | 0.968812 | 0.969118 | 0.972940 | 0.969023 | 0.002834 |
| 4 | 0.023506 | 0.000631 | 0.001776 | 0.000067 | 5 | 3 | 3 | 10 | {'max_depth': 5, 'max_features': 3, 'min_sampl... | 0.937799 | ... | 0.970031 | 0.970031 | 0.974312 | 0.972477 | 0.974312 | 0.970188 | 0.973857 | 0.973399 | 0.972616 | 0.001729 |
5 rows × 59 columns
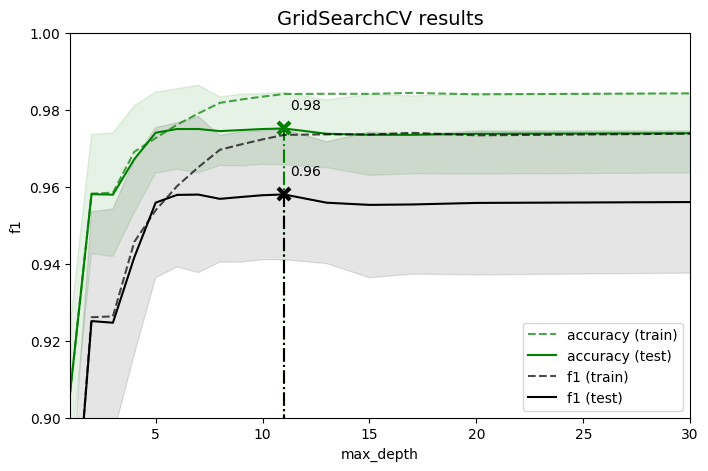
# https://scikit-learn.org/dev/auto_examples/model_selection/plot_multi_metric_evaluation.html
plt.figure(figsize=(8, 5))
plt.title("GridSearchCV results", fontsize=14)
plt.xlabel("max_depth")
plt.ylabel("f1")
ax = plt.gca()
ax.set_xlim(1, 30)
ax.set_ylim(0.9, 1)
X_axis = np.array(results["param_max_depth"].data, dtype=float)
for scorer, color in zip(sorted(scoring), ["g", "k"]):
for sample, style in (("train", "--"), ("test", "-")):
sample_score_mean = results["mean_%s_%s" % (sample, scorer)]
sample_score_std = results["std_%s_%s" % (sample, scorer)]
ax.fill_between(
X_axis,
sample_score_mean - sample_score_std,
sample_score_mean + sample_score_std,
alpha=0.1 if sample == "test" else 0,
color=color,
)
ax.plot(
X_axis,
sample_score_mean,
style,
color=color,
alpha=1 if sample == "test" else 0.7,
label="%s (%s)" % (scorer, sample),
)
best_index = np.nonzero(results["rank_test_%s" % scorer] == 1)[0][0]
best_score = results["mean_test_%s" % scorer][best_index]
# Plot a dotted vertical line at the best score for that scorer marked by x
ax.plot(
[
X_axis[best_index],
]
* 2,
[0, best_score],
linestyle="-.",
color=color,
marker="x",
markeredgewidth=3,
ms=8,
)
# Annotate the best score for that scorer
ax.annotate("%0.2f" % best_score, (X_axis[best_index] + 0.3, best_score + 0.005))
plt.legend(loc="best")
plt.grid(False)
plt.savefig("GridSearchCV_results.png", dpi=300)
plt.show()
Final model#
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
(5086, 10) (5086,)
(2181, 10) (2181,)
rfc = RandomForestClassifier(
max_depth=17,
max_features=10,
min_samples_leaf=3,
n_estimators=50,
random_state=42,
oob_score=True,
)
# rfc = RandomForestClassifier(n_estimators=250, random_state=1)
rfc.fit(X_train, y_train)
RandomForestClassifier(max_depth=17, max_features=10, min_samples_leaf=3,
n_estimators=50, oob_score=True, random_state=42)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestClassifier(max_depth=17, max_features=10, min_samples_leaf=3,
n_estimators=50, oob_score=True, random_state=42)features = X.columns
importances = rfc.feature_importances_
indices = np.argsort(importances)[::-1]
for index, i in enumerate(indices[:10]):
print("{}.\t#{}\t{:.3f}\t{}".format(index + 1, i, importances[i], features[i]))
1. #2 0.362 Max Packet Length
2. #0 0.211 Average Packet Size
3. #6 0.150 Fwd IAT Std
4. #3 0.126 Fwd IAT Min
5. #5 0.054 Total Length of Fwd Packets
6. #7 0.053 Flow IAT Mean
7. #9 0.026 Fwd Header Length
8. #4 0.014 Fwd Packet Length Mean
9. #8 0.003 Fwd Packet Length Max
10. #1 0.001 Flow Bytes/s
y_pred = rfc.predict(X_test)
confusion_matrix(y_test, y_pred)
array([[1491, 25],
[ 43, 622]])
import sklearn.metrics as metrics
accuracy = metrics.accuracy_score(y_test, y_pred)
precision = metrics.precision_score(y_test, y_pred)
recall = metrics.recall_score(y_test, y_pred)
f1 = metrics.f1_score(y_test, y_pred)
print("Accuracy =", accuracy)
print("Precision =", precision)
print("Recall =", recall)
print("F1 =", f1)
Accuracy = 0.9688216414488766
Precision = 0.9613601236476044
Recall = 0.9353383458646617
F1 = 0.948170731707317
Model approbation#
df = df_balanced.copy()
df["Label"] = df["Label"].apply(lambda x: 0 if x == "BENIGN" else 1)
y_test = df["Label"].values
X_test = df[webattack_features]
print(X_test.shape, y_test.shape)
(7267, 10) (7267,)
X_test.head()
| Average Packet Size | Flow Bytes/s | Max Packet Length | Fwd IAT Min | Fwd Packet Length Mean | Total Length of Fwd Packets | Fwd IAT Std | Flow IAT Mean | Fwd Packet Length Max | Fwd Header Length | |
|---|---|---|---|---|---|---|---|---|---|---|
| 15 | 83.500000 | 4.857268e+03 | 77 | 0.0 | 45.000000 | 45 | 0.000000 | 25117.000000 | 45 | 32 |
| 73 | 80.000000 | 1.633136e+06 | 94 | 4.0 | 44.000000 | 88 | 0.000000 | 56.333333 | 44 | 64 |
| 90 | 80.000000 | 1.380000e+06 | 94 | 47.0 | 44.000000 | 88 | 0.000000 | 66.666667 | 44 | 64 |
| 140 | 414.533333 | 5.871577e+06 | 1555 | 1.0 | 345.555556 | 3110 | 284.408126 | 75.642857 | 1555 | 304 |
| 212 | 94.250000 | 3.018519e+06 | 112 | 1.0 | 51.000000 | 102 | 0.000000 | 36.000000 | 51 | 64 |
import time
seconds = time.time()
y_pred = rfc.predict(X_test)
print("Total operation time:", time.time() - seconds, "seconds")
print("Benign records detected (0), attacks detected (1):")
unique, counts = np.unique(y_pred, return_counts=True)
dict(zip(unique, counts))
Total operation time: 0.010741710662841797 seconds
Benign records detected (0), attacks detected (1):
{0: 5120, 1: 2147}
Confusion matrix:
0 1 - predicted value (Wikipedia uses different convention for axes)
0 TN FP
1 FN TP
confusion_matrix(y_test, y_pred)
array([[5035, 52],
[ 85, 2095]])
accuracy = metrics.accuracy_score(y_test, y_pred)
precision = metrics.precision_score(y_test, y_pred)
recall = metrics.recall_score(y_test, y_pred)
f1 = metrics.f1_score(y_test, y_pred)
print("Accuracy =", accuracy)
print("Precision =", precision)
print("Recall =", recall)
print("F1 =", f1)
Accuracy = 0.9811476537773497
Precision = 0.975780158360503
Recall = 0.9610091743119266
F1 = 0.9683383406517218
predict = pd.DataFrame({"Predict": rfc.predict(X_test)})
label = pd.DataFrame({"Label": y_test})
result = X_test.join(label).join(predict)
display("The following is point that are predicted to be intrusion (anomaly)")
result[result["Predict"] == 1]
'The following is point that are predicted to be intrusion (anomaly)'
| Average Packet Size | Flow Bytes/s | Max Packet Length | Fwd IAT Min | Fwd Packet Length Mean | Total Length of Fwd Packets | Fwd IAT Std | Flow IAT Mean | Fwd Packet Length Max | Fwd Header Length | Label | Predict | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 704 | 7.500000 | 6.000000e+05 | 6 | 0.0 | 6.000000 | 6 | 0.000000e+00 | 1.333333e+01 | 6 | 20 | 1.0 | 1.0 |
| 756 | 48.000000 | 1.134752e+06 | 48 | 3.0 | 32.000000 | 64 | 0.000000e+00 | 4.700000e+01 | 32 | 64 | 1.0 | 1.0 |
| 1047 | 87.500000 | 5.073501e+03 | 118 | 4.0 | 38.000000 | 76 | 0.000000e+00 | 2.049867e+04 | 38 | 40 | 1.0 | 1.0 |
| 1075 | 141.000000 | 1.098433e+02 | 200 | 0.0 | 41.000000 | 41 | 0.000000e+00 | 2.194035e+06 | 41 | 32 | 1.0 | 1.0 |
| 1083 | 271.333333 | 7.509294e+05 | 796 | 2.0 | 269.333333 | 808 | 7.580185e+02 | 5.380000e+02 | 796 | 60 | 1.0 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4591 | 146.500000 | 3.885334e+03 | 183 | 0.0 | 55.000000 | 55 | 0.000000e+00 | 6.125600e+04 | 55 | 20 | 1.0 | 1.0 |
| 4600 | 80.500000 | 1.192036e+04 | 101 | 3.0 | 40.000000 | 80 | 0.000000e+00 | 7.885667e+03 | 40 | 64 | 1.0 | 1.0 |
| 4709 | 87.250000 | 6.516699e+03 | 119 | 3.0 | 37.000000 | 74 | 0.000000e+00 | 1.595900e+04 | 37 | 40 | 1.0 | 1.0 |
| 4855 | 104.000000 | 1.900135e+03 | 108 | 0.0 | 50.000000 | 50 | 0.000000e+00 | 8.315200e+04 | 50 | 20 | 1.0 | 1.0 |
| 4938 | 257.538461 | 5.846547e+02 | 1460 | 4.0 | 77.125000 | 617 | 1.965194e+06 | 4.772048e+05 | 342 | 172 | 1.0 | 1.0 |
61 rows × 12 columns
display("The following is point that are predicted to be genuine")
result[result["Predict"] == 0]
'The following is point that are predicted to be genuine'
| Average Packet Size | Flow Bytes/s | Max Packet Length | Fwd IAT Min | Fwd Packet Length Mean | Total Length of Fwd Packets | Fwd IAT Std | Flow IAT Mean | Fwd Packet Length Max | Fwd Header Length | Label | Predict | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15 | 83.500000 | 4.857268e+03 | 77 | 0.0 | 45.000000 | 45 | 0.000000e+00 | 25117.000000 | 45 | 32 | 0.0 | 0.0 |
| 73 | 80.000000 | 1.633136e+06 | 94 | 4.0 | 44.000000 | 88 | 0.000000e+00 | 56.333333 | 44 | 64 | 0.0 | 0.0 |
| 90 | 80.000000 | 1.380000e+06 | 94 | 47.0 | 44.000000 | 88 | 0.000000e+00 | 66.666667 | 44 | 64 | 0.0 | 0.0 |
| 140 | 414.533333 | 5.871577e+06 | 1555 | 1.0 | 345.555556 | 3110 | 2.844081e+02 | 75.642857 | 1555 | 304 | 0.0 | 0.0 |
| 212 | 94.250000 | 3.018519e+06 | 112 | 1.0 | 51.000000 | 102 | 0.000000e+00 | 36.000000 | 51 | 64 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7141 | 80.000000 | 1.308057e+06 | 94 | 48.0 | 44.000000 | 88 | 0.000000e+00 | 70.333333 | 44 | 40 | 0.0 | 0.0 |
| 7143 | 2.400000 | 1.538462e+05 | 6 | 0.0 | 0.000000 | 0 | 0.000000e+00 | 19.500000 | 0 | 32 | 0.0 | 0.0 |
| 7166 | 94.250000 | 2.000000e+06 | 112 | 4.0 | 51.000000 | 102 | 0.000000e+00 | 54.333333 | 51 | 40 | 0.0 | 0.0 |
| 7230 | 43.636364 | 9.050426e+01 | 223 | 48.0 | 46.142857 | 323 | 2.126298e+06 | 530361.800000 | 223 | 160 | 0.0 | 0.0 |
| 7254 | 139.000000 | 1.533367e+03 | 186 | 0.0 | 46.000000 | 46 | 0.000000e+00 | 151301.000000 | 46 | 32 | 0.0 | 0.0 |
171 rows × 12 columns