Module 6: Generative AI for Cyber Security#
Fine-tunning a model for Cyber Security#
Fine-tuning a language model in the context of LLMs (Masked Language Models like BERT), refers to the process of taking a pre-trained language model and further training it on a smaller, task-specific dataset to adapt it to a specific downstream task. The idea is to leverage the knowledge learned during the initial pre-training on a large corpus and then fine-tune the model to perform well on a specific task of interest.
Pre-training on a Large Corpus
Initially, the language model is pre-trained on a large and diverse dataset. During this phase, the model learns general language patterns, syntax, and contextual relationships between words.
Task-Specific Data
After pre-training, the model is fine-tuned on a smaller dataset that is specific to the task you want the model to perform well on. This dataset is typically labeled and consists of examples relevant to the downstream task.
Architecture and Parameters
The architecture of the model remains the same, but the parameters learned during pre-training are further adjusted based on the task-specific data. The fine-tuning process updates the weights of the model to make it more suited for the specific task.
Task-Specific Objective Function
The objective function used during fine-tuning is tailored to the downstream task. For example, in classification tasks, the model might be fine-tuned using a cross-entropy loss function.
Learning Rate and Training Hyperparameters
Fine-tuning often involves adjusting the learning rate and other hyperparameters to ensure effective training on the smaller dataset. This helps prevent overfitting and encourages the model to adapt to the specific task.
Transfer of Knowledge
The knowledge gained during pre-training, such as understanding of language structures and semantics, is transferred to the task-specific model. Fine-tuning allows the model to specialize without losing the general language understanding acquired during pre-training.
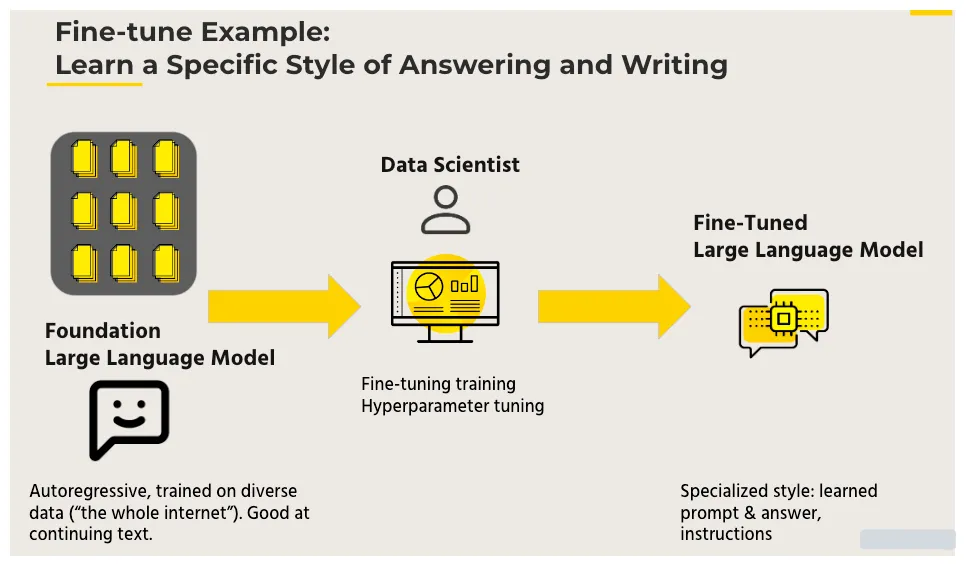
Fine-tuning is particularly useful when you have a limited amount of task-specific data. By starting with a pre-trained model, you can benefit from the knowledge embedded in the model and fine-tune it to achieve good performance on your specific task, even with a smaller dataset. This approach has been successful in various natural language processing (NLP) tasks, ranging from sentiment analysis to named entity recognition.
Case Study: SecureBret#
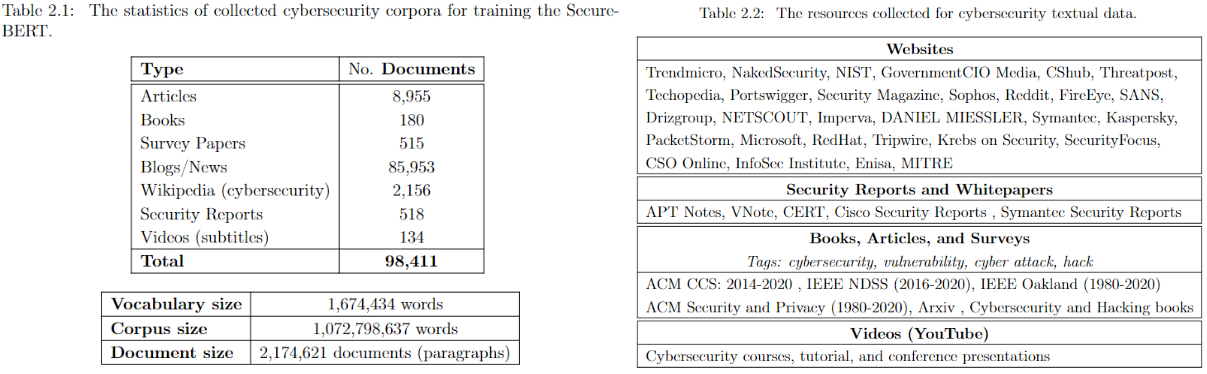
SecureBERT is a domain-specific language model to represent cybersecurity textual data which is trained on a large amount of in-domain text crawled from online resources.
SecureBERT can be used as the base model for any downstream task including text classification, NER, Seq-to-Seq, QA, etc.
SecureBERT has demonstrated significantly higher performance in predicting masked words within the text when compared to existing models like RoBERTa (base and large), SciBERT, and SecBERT.
SecureBERT has also demonstrated promising performance in preserving general English language understanding (representation).
!pip install transformers
!pip install torch
!pip install tokenizers
Requirement already satisfied: transformers in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (4.23.0)
Requirement already satisfied: filelock in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from transformers) (3.13.1)
Requirement already satisfied: huggingface-hub<1.0,>=0.10.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from transformers) (0.20.2)
Requirement already satisfied: numpy>=1.17 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from transformers) (1.26.3)
Requirement already satisfied: packaging>=20.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from transformers) (23.2)
Requirement already satisfied: pyyaml>=5.1 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from transformers) (6.0.1)
Requirement already satisfied: regex!=2019.12.17 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from transformers) (2023.12.25)
Requirement already satisfied: requests in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from transformers) (2.31.0)
Requirement already satisfied: tokenizers!=0.11.3,<0.14,>=0.11.1 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from transformers) (0.13.3)
Requirement already satisfied: tqdm>=4.27 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from transformers) (4.66.1)
Requirement already satisfied: fsspec>=2023.5.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from huggingface-hub<1.0,>=0.10.0->transformers) (2023.10.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from huggingface-hub<1.0,>=0.10.0->transformers) (4.9.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from requests->transformers) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from requests->transformers) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from requests->transformers) (2.2.0)
Requirement already satisfied: certifi>=2017.4.17 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from requests->transformers) (2023.11.17)
Requirement already satisfied: torch in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (2.2.0)
Requirement already satisfied: filelock in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (3.13.1)
Requirement already satisfied: typing-extensions>=4.8.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (4.9.0)
Requirement already satisfied: sympy in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (1.12)
Requirement already satisfied: networkx in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (3.2.1)
Requirement already satisfied: jinja2 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (3.1.3)
Requirement already satisfied: fsspec in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (2023.10.0)
Requirement already satisfied: nvidia-cuda-nvrtc-cu12==12.1.105 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (12.1.105)
Requirement already satisfied: nvidia-cuda-runtime-cu12==12.1.105 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (12.1.105)
Requirement already satisfied: nvidia-cuda-cupti-cu12==12.1.105 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (12.1.105)
Requirement already satisfied: nvidia-cudnn-cu12==8.9.2.26 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (8.9.2.26)
Requirement already satisfied: nvidia-cublas-cu12==12.1.3.1 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (12.1.3.1)
Requirement already satisfied: nvidia-cufft-cu12==11.0.2.54 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (11.0.2.54)
Requirement already satisfied: nvidia-curand-cu12==10.3.2.106 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (10.3.2.106)
Requirement already satisfied: nvidia-cusolver-cu12==11.4.5.107 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (11.4.5.107)
Requirement already satisfied: nvidia-cusparse-cu12==12.1.0.106 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (12.1.0.106)
Requirement already satisfied: nvidia-nccl-cu12==2.19.3 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (2.19.3)
Requirement already satisfied: nvidia-nvtx-cu12==12.1.105 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (12.1.105)
Requirement already satisfied: triton==2.2.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch) (2.2.0)
Requirement already satisfied: nvidia-nvjitlink-cu12 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from nvidia-cusolver-cu12==11.4.5.107->torch) (12.3.101)
Requirement already satisfied: MarkupSafe>=2.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from jinja2->torch) (2.1.5)
Requirement already satisfied: mpmath>=0.19 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from sympy->torch) (1.3.0)
Requirement already satisfied: tokenizers in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (0.13.3)
from transformers import RobertaTokenizer, RobertaModel
import torch
tokenizer = RobertaTokenizer.from_pretrained("ehsanaghaei/SecureBERT")
model = RobertaModel.from_pretrained("ehsanaghaei/SecureBERT")
inputs = tokenizer("This is SecureBERT!", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
import torch
import transformers
from transformers import RobertaTokenizer, RobertaTokenizerFast
tokenizer = RobertaTokenizerFast.from_pretrained("ehsanaghaei/SecureBERT")
model = transformers.RobertaForCausalLM.from_pretrained("ehsanaghaei/SecureBERT")
def predict_mask(sent, tokenizer, model, topk=10, print_results=True):
token_ids = tokenizer.encode(sent, return_tensors="pt")
masked_position = (token_ids.squeeze() == tokenizer.mask_token_id).nonzero()
masked_pos = [mask.item() for mask in masked_position]
words = []
with torch.no_grad():
output = model(token_ids)
last_hidden_state = output[0].squeeze()
list_of_list = []
for index, mask_index in enumerate(masked_pos):
mask_hidden_state = last_hidden_state[mask_index]
idx = torch.topk(mask_hidden_state, k=topk, dim=0)[1]
words = [tokenizer.decode(i.item()).strip() for i in idx]
words = [w.replace(" ", "") for w in words]
list_of_list.append(words)
return list_of_list
from IPython.display import display, HTML
import html
def input_masked_sentence(input):
def escape_mask(text):
return text.replace("<mask>", "<‍mask>")
display(HTML(f"<b>Input:</b> {escape_mask(input)}"))
for output in predict_mask(input, tokenizer, model):
display(HTML(f"<b>SecureBert:</b> {' | '.join(output)}"))
Some weights of the model checkpoint at ehsanaghaei/SecureBERT were not used when initializing RobertaModel: ['lm_head.layer_norm.weight', 'lm_head.dense.bias', 'lm_head.layer_norm.bias', 'lm_head.bias', 'lm_head.dense.weight']
- This IS expected if you are initializing RobertaModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of RobertaModel were not initialized from the model checkpoint at ehsanaghaei/SecureBERT and are newly initialized: ['roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
If you want to use `RobertaLMHeadModel` as a standalone, add `is_decoder=True.`
The <mask> token is commonly used in the context of masked language models (LLMs) or masked language model pre-training. This approach is a type of unsupervised learning where a model is trained to predict missing or masked tokens in a sequence of text. The <mask> token is used to represent the positions in the input text where tokens are masked or hidden during training.
Here’s a general overview of how the <mask> token works in the context of LLMs:
Masking during Training:
During the pre-training phase, a certain percentage of tokens in the input text are randomly selected to be masked. These masked tokens are then replaced with the <mask> token.
The model is trained to predict the original identity of the masked tokens based on the context provided by the surrounding tokens.
Objective Function:
The objective function during training is typically to maximize the likelihood of predicting the correct tokens at the masked positions. This training process helps the model learn contextual relationships and dependencies between words in a given language.

Fine-Tuning and Downstream Tasks:
After pre-training, the model can be fine-tuned on specific downstream tasks (such as text classification, named entity recognition, etc.). The knowledge gained during pre-training helps the model perform well on a range of natural language processing (NLP) tasks. Prediction during Inference:
During inference or when using the model for downstream tasks, the <mask> token can be used to predict missing tokens in a given sequence. For example, if you provide a sentence with some tokens replaced by <mask>, the model can predict the most likely tokens for those masked positions.
Overall, the <mask> token is a key element in the training process of LLMs, enabling them to learn rich representations of language and perform well on a variety of NLP tasks. The most well-known model that uses this approach is BERT (Bidirectional Encoder Representations from Transformers).
input_masked_sentence(
"Adversaries may also compromise sites then include <mask> content designed to collect website authentication cookies from visitors."
)
input_masked_sentence(
"One example of this is MS14-068, which targets <mask> and can be used to forge Kerberos tickets using domain user permissions."
)
input_masked_sentence("Paris is the <mask> of France.")
input_masked_sentence("Virus causes <mask>.")
input_masked_sentence("Sending huge amount of packets through network leads to <mask>.")
input_masked_sentence(
"A <mask> injection occurs when an attacker inserts malicious code into a server"
)
Using LLMs as Offensive Generative AI#
Offensive Generative AI Model#
Offensive security is the practice of actively seeking out vulnerabilities in an organization’s cybersecurity. It often involves using similar tactics as attackers and might include red teaming, penetration testing and vulnerability assessments. Offensive security can be shortened to “OffSec.”
Offensive generative AI refers natural language processing (NLP) and machine learning techniques, that are designed or trained to produce content that is offensive, harmful, or inappropriate in some way. This content could include hate speech, derogatory language, violent or threatening messages, misinformation, or other forms of harmful content. Malicious AI can weaponising generative AI to improve the monetisation of their attacks, which will stem from a surge in ransomware attacks and phishing campaigns.
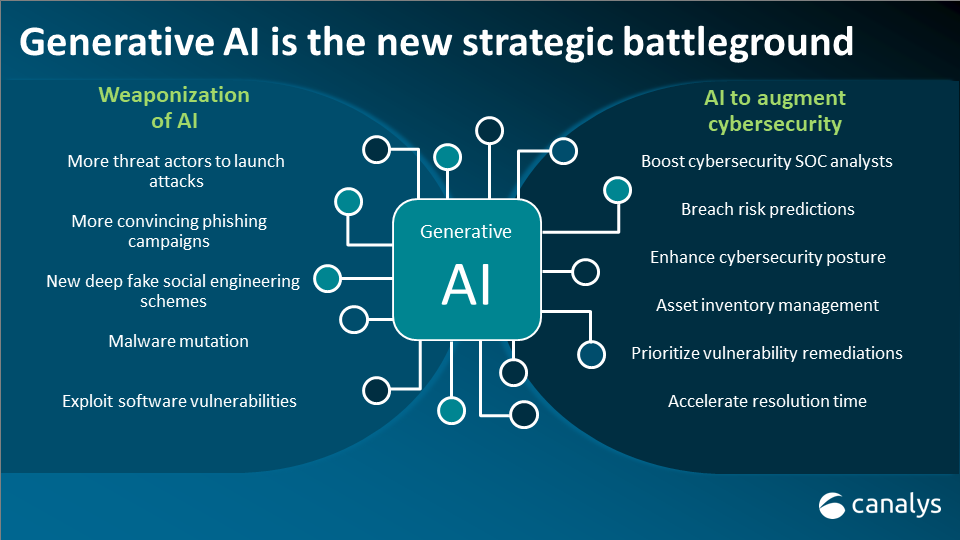
Such AI systems can pose significant ethical and societal challenges. They have the potential to spread harmful messages at scale, amplify existing biases and prejudices present in the training data, and contribute to the proliferation of toxic online environments. Offensive generative AI can be used maliciously by individuals or groups to harass others, manipulate public opinion, or undermine trust in information sources.
Generative model for cracking password#
Generative AI poses several dangers for password cracking:
Speed and Efficiency: Generative AI can significantly speed up the process of password cracking by generating and testing a vast number of possible passwords in a short amount of time. This can make it much more efficient for attackers to breach password-protected systems or accounts.
Sophisticated Attack Techniques: Generative AI can employ sophisticated techniques, such as neural networks or reinforcement learning, to generate passwords that are more likely to be successful in cracking password hashes or bypassing authentication mechanisms.
Adaptability: Generative AI models can adapt to different patterns and structures commonly found in passwords, such as common words, phrases, or character combinations. This adaptability makes them more effective at cracking passwords that may not be easily guessable or vulnerable to traditional brute-force methods.
Privacy Risks: If generative AI is used for password cracking, it could compromise the privacy and security of individuals or organizations by gaining unauthorized access to sensitive information stored behind password-protected systems or accounts.
Scale and Automation: Generative AI can be deployed at scale and automated, allowing attackers to launch large-scale password cracking attacks against multiple targets simultaneously, increasing the potential impact and severity of security breaches.imators.
PassGPT#
PassGPT is an LLM trained on password leaks for password generation. PassGPT outperforms existing methods based by guessing twice as many previously unseen passwords. PassGPT also contains the concept of guided password generation, where they leverage PassGPT sampling procedure to generate passwords matching arbitrary constraints.
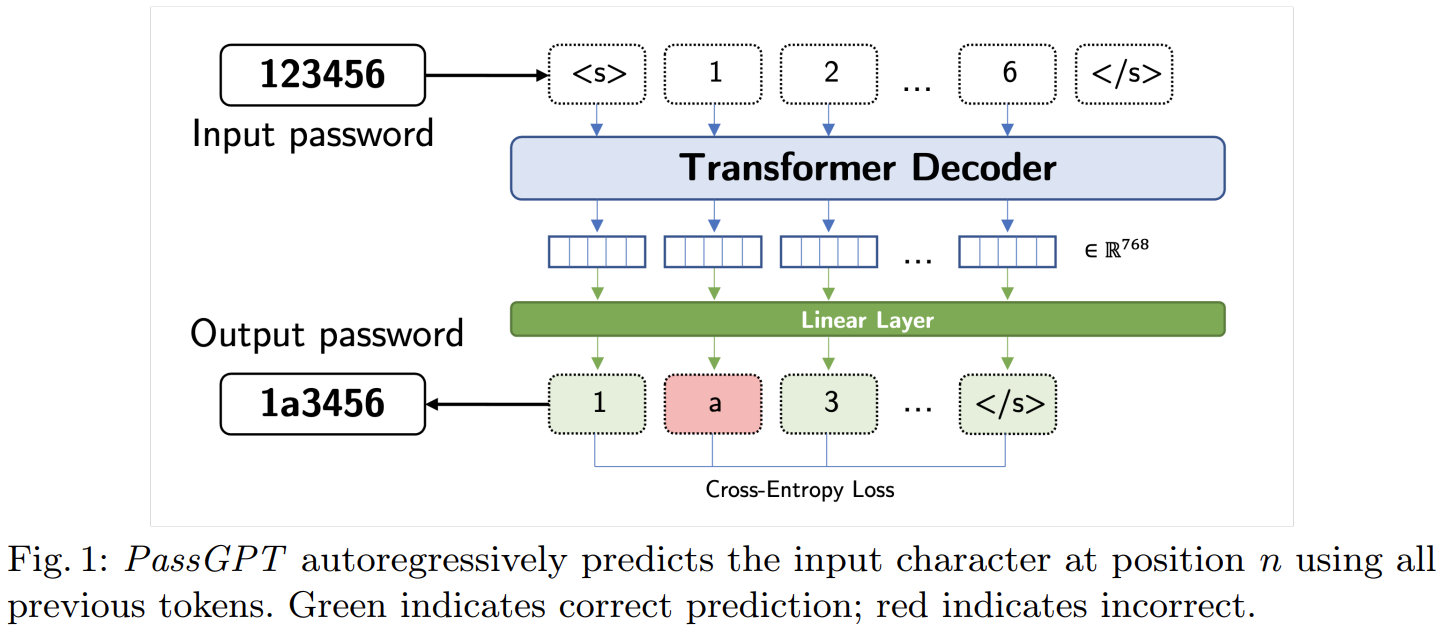
from transformers import GPT2LMHeadModel
from transformers import RobertaTokenizerFast
import torch
tokenizer = RobertaTokenizerFast.from_pretrained(
"javirandor/passgpt-10characters",
max_len=12,
padding="max_length",
truncation=True,
do_lower_case=False,
strip_accents=False,
mask_token="<mask>",
unk_token="<unk>",
pad_token="<pad>",
truncation_side="right",
)
model = GPT2LMHeadModel.from_pretrained("javirandor/passgpt-10characters").eval()
NUM_GENERATIONS = 1
def generate_password(prefix, max_length=12):
start_token = tokenizer.encode(prefix)
start_token = start_token[0:-1]
# Generate passwords sampling from the beginning of password token
g = model.generate(
torch.tensor([start_token]),
# do_sample=True,
num_return_sequences=NUM_GENERATIONS,
max_length=max_length + 1,
pad_token_id=tokenizer.pad_token_id,
bad_words_ids=[[tokenizer.bos_token_id]],
)
# Remove start of sentence token
g = g[:, 1:]
decoded = tokenizer.batch_decode(g.tolist())
decoded_clean = [
i.split("</s>")[0] for i in decoded
] # Get content before end of password token
# Print your sampled passwords!
return decoded_clean
seedgen = torch.manual_seed(0)
Learning the behaviour of human’s password creation#
The following are generating the most likely password that people choose based on big data
generate_password("")
['0876060007']
generate_password(prefix="pas", max_length=8)
['password']
generate_password(prefix="qw", max_length=6)
['qwerty']
generate_password(prefix="ilo", max_length=12)
['iloveme123']
generate_password(prefix="John", max_length=12)
['Johnny1994']
You can also do a conditional password generation
import string
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
DEVICE = "cpu"
# Map each of the desired character groups into their corresponding ids (as given by the tokenizer)
lowercase = list(string.ascii_lowercase)
uppercase = list(string.ascii_uppercase)
digits = list(string.digits)
punctuation = list(string.punctuation)
lowercase_tokens = tokenizer(lowercase, add_special_tokens=False).input_ids
uppercase_tokens = tokenizer(uppercase, add_special_tokens=False).input_ids
digits_tokens = tokenizer(digits, add_special_tokens=False).input_ids
punctuation_tokens = tokenizer(punctuation, add_special_tokens=False).input_ids
# All possible tokens in our model
all_tokens = [[i] for i in range(len(tokenizer))]
def conditional_generation(template, num_generations=1):
generated = 0
generations = []
while generated < num_generations:
generation = torch.tensor([tokenizer.bos_token_id]).unsqueeze(0)
current_length = 1
for char in template:
if char == "l":
bad_tokens = [i for i in all_tokens if i not in lowercase_tokens]
elif char == "u":
bad_tokens = [i for i in all_tokens if i not in uppercase_tokens]
elif char == "d":
bad_tokens = [i for i in all_tokens if i not in digits_tokens]
elif char == "p":
bad_tokens = [i for i in all_tokens if i not in punctuation_tokens]
else:
bad_tokens = [[tokenizer.eos_token_id]]
generation = model.generate(
generation.to(DEVICE),
do_sample=True,
max_length=current_length + 1,
pad_token_id=tokenizer.pad_token_id,
num_return_sequences=1,
bad_words_ids=bad_tokens,
)
current_length += 1
if not 2 in generation.flatten():
generations.append(generation)
generated += 1
return tokenizer.batch_decode(torch.cat(generations, 0)[:, 1:])
Conditional Password Generation#
One of the main advantages of Generative AI is the possibility of generating passwords under arbitrary constraints. In this template code, we have created five different groups of characters that we can sample from at each position:
l: lowercase lettersu: uppercase lettersd: digitsp: punctuation*: any character in the vocabulary
You can create any template by combining these. For example, lllldd will generate passwords starting with four lowercase letters and finishing with two digits.
Feel free to create your own character groups below.
conditional_generation("lllldd", 5)
['owen32', 'will14', 'bubb12', 'rgdl15', 'pinc04']
conditional_generation("u*****lldd", 5)
['KTMRGEma12', 'Valenbir10', 'Brandonm93', 'Brickfor23', 'Bradbitc10']
!pip install facenet_pytorch opencv-python grad-cam
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Requirement already satisfied: facenet_pytorch in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (2.5.3)
Requirement already satisfied: opencv-python in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (4.9.0.80)
Requirement already satisfied: grad-cam in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (1.5.0)
Requirement already satisfied: numpy in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from facenet_pytorch) (1.26.3)
Requirement already satisfied: requests in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from facenet_pytorch) (2.31.0)
Requirement already satisfied: torchvision in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from facenet_pytorch) (0.17.0)
Requirement already satisfied: pillow in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from facenet_pytorch) (10.2.0)
Requirement already satisfied: torch>=1.7.1 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from grad-cam) (2.2.0)
Requirement already satisfied: ttach in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from grad-cam) (0.0.3)
Requirement already satisfied: tqdm in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from grad-cam) (4.66.1)
Requirement already satisfied: matplotlib in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from grad-cam) (3.8.2)
Requirement already satisfied: scikit-learn in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from grad-cam) (1.4.0)
Requirement already satisfied: filelock in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (3.13.1)
Requirement already satisfied: typing-extensions>=4.8.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (4.9.0)
Requirement already satisfied: sympy in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (1.12)
Requirement already satisfied: networkx in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (3.2.1)
Requirement already satisfied: jinja2 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (3.1.3)
Requirement already satisfied: fsspec in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (2023.10.0)
Requirement already satisfied: nvidia-cuda-nvrtc-cu12==12.1.105 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (12.1.105)
Requirement already satisfied: nvidia-cuda-runtime-cu12==12.1.105 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (12.1.105)
Requirement already satisfied: nvidia-cuda-cupti-cu12==12.1.105 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (12.1.105)
Requirement already satisfied: nvidia-cudnn-cu12==8.9.2.26 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (8.9.2.26)
Requirement already satisfied: nvidia-cublas-cu12==12.1.3.1 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (12.1.3.1)
Requirement already satisfied: nvidia-cufft-cu12==11.0.2.54 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (11.0.2.54)
Requirement already satisfied: nvidia-curand-cu12==10.3.2.106 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (10.3.2.106)
Requirement already satisfied: nvidia-cusolver-cu12==11.4.5.107 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (11.4.5.107)
Requirement already satisfied: nvidia-cusparse-cu12==12.1.0.106 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (12.1.0.106)
Requirement already satisfied: nvidia-nccl-cu12==2.19.3 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (2.19.3)
Requirement already satisfied: nvidia-nvtx-cu12==12.1.105 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (12.1.105)
Requirement already satisfied: triton==2.2.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from torch>=1.7.1->grad-cam) (2.2.0)
Requirement already satisfied: nvidia-nvjitlink-cu12 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from nvidia-cusolver-cu12==11.4.5.107->torch>=1.7.1->grad-cam) (12.3.101)
Requirement already satisfied: contourpy>=1.0.1 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from matplotlib->grad-cam) (1.2.0)
Requirement already satisfied: cycler>=0.10 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from matplotlib->grad-cam) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from matplotlib->grad-cam) (4.47.2)
Requirement already satisfied: kiwisolver>=1.3.1 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from matplotlib->grad-cam) (1.4.5)
Requirement already satisfied: packaging>=20.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from matplotlib->grad-cam) (23.2)
Requirement already satisfied: pyparsing>=2.3.1 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from matplotlib->grad-cam) (3.1.1)
Requirement already satisfied: python-dateutil>=2.7 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from matplotlib->grad-cam) (2.8.2)
Requirement already satisfied: importlib-resources>=3.2.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from matplotlib->grad-cam) (6.1.1)
Requirement already satisfied: charset-normalizer<4,>=2 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from requests->facenet_pytorch) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from requests->facenet_pytorch) (3.6)
Requirement already satisfied: urllib3<3,>=1.21.1 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from requests->facenet_pytorch) (2.2.0)
Requirement already satisfied: certifi>=2017.4.17 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from requests->facenet_pytorch) (2023.11.17)
Requirement already satisfied: scipy>=1.6.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from scikit-learn->grad-cam) (1.12.0)
Requirement already satisfied: joblib>=1.2.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from scikit-learn->grad-cam) (1.3.2)
Requirement already satisfied: threadpoolctl>=2.0.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from scikit-learn->grad-cam) (3.2.0)
Requirement already satisfied: zipp>=3.1.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from importlib-resources>=3.2.0->matplotlib->grad-cam) (3.17.0)
Requirement already satisfied: six>=1.5 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from python-dateutil>=2.7->matplotlib->grad-cam) (1.16.0)
Requirement already satisfied: MarkupSafe>=2.0 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from jinja2->torch>=1.7.1->grad-cam) (2.1.5)
Requirement already satisfied: mpmath>=0.19 in /home/soraxas/micromamba/envs/wsu/lib/python3.9/site-packages (from sympy->torch>=1.7.1->grad-cam) (1.3.0)
Defensive Generative AI#
After having a look at how generative AI can be destructive, let’s have a look at using AI in a more defensive manner.
Defensive Generative AI refers to a branch of artificial intelligence (AI) research that focuses on developing systems capable of defending against attacks targeting generative models. Generative models, such as generative adversarial networks (GANs) or variational autoencoders (VAEs), are AI architectures designed to generate new data samples that resemble a training dataset. These models have shown great potential in various applications, including image generation, text generation, and data synthesis.
However, like any AI system, generative models are vulnerable to attacks. Adversarial attacks against generative models can involve manipulating input data to generate outputs that mislead or compromise the model’s performance. These attacks can have significant implications, such as generating fake images that appear real or altering text generation models to produce misleading or harmful content.
Defensive Generative AI aims to develop techniques and strategies to mitigate the risks associated with adversarial attacks on generative models. This may involve developing robust training methods, designing algorithms that can detect adversarial inputs, or incorporating additional security measures into generative models to enhance their resilience against attacks.
Detecting Deepfake#
Deepfake refers to a manipulated or synthesized media, typically videos or images, where a person’s likeness or voice is replaced with that of another individual using deep learning techniques, particularly generative adversarial networks (GANs) or similar deep learning architectures. The term “deepfake” is a combination of “deep learning” and “fake.”
Deepfakes have gained notoriety for their potential to deceive or manipulate viewers by creating realistic but entirely fabricated content. They can be used to superimpose faces onto bodies in videos, alter facial expressions or lip movements to match different audio tracks, or even create entirely synthetic videos of people saying or doing things they never actually did.

Lets load up a model that can detects fake images by focusing on various local region on the faces.
![ -f examples.zip ] || wget https://huggingface.co/spaces/aaronespasa/deepfake-detection/resolve/main/examples.zip?download=true -O examples.zip
![ -f resnetinceptionv1_epoch_32.pth ] || wget https://huggingface.co/spaces/aaronespasa/deepfake-detection/resolve/main/resnetinceptionv1_epoch_32.pth?download=true -O resnetinceptionv1_epoch_32.pth
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
import torch
import torch.nn.functional as F
from facenet_pytorch import MTCNN, InceptionResnetV1
import os
import numpy as np
from PIL import Image
import zipfile
import cv2
from pytorch_grad_cam import GradCAM
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
from pytorch_grad_cam.utils.image import show_cam_on_image
with zipfile.ZipFile("examples.zip", "r") as zip_ref:
zip_ref.extractall(".")
DEVICE = "cpu"
mtcnn = MTCNN(select_largest=False, post_process=False, device=DEVICE).to(DEVICE).eval()
model = InceptionResnetV1(
pretrained="vggface2", classify=True, num_classes=1, device=DEVICE
)
checkpoint = torch.load(
"resnetinceptionv1_epoch_32.pth", map_location=torch.device("cpu")
)
model.load_state_dict(checkpoint["model_state_dict"])
model.to(DEVICE)
model.eval()
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
InceptionResnetV1(
(conv2d_1a): BasicConv2d(
(conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(conv2d_2a): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(conv2d_2b): BasicConv2d(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(maxpool_3a): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2d_3b): BasicConv2d(
(conv): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(80, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(conv2d_4a): BasicConv2d(
(conv): Conv2d(80, 192, kernel_size=(3, 3), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(conv2d_4b): BasicConv2d(
(conv): Conv2d(192, 256, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(repeat_1): Sequential(
(0): Block35(
(branch0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(96, 256, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(1): Block35(
(branch0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(96, 256, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(2): Block35(
(branch0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(96, 256, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(3): Block35(
(branch0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(96, 256, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(4): Block35(
(branch0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(96, 256, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
)
(mixed_6a): Mixed_6a(
(branch0): BasicConv2d(
(conv): Conv2d(256, 384, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(256, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(192, 256, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(branch2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(repeat_2): Sequential(
(0): Block17(
(branch0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(256, 896, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(1): Block17(
(branch0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(256, 896, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(2): Block17(
(branch0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(256, 896, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(3): Block17(
(branch0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(256, 896, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(4): Block17(
(branch0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(256, 896, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(5): Block17(
(branch0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(256, 896, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(6): Block17(
(branch0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(256, 896, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(7): Block17(
(branch0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(256, 896, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(8): Block17(
(branch0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(256, 896, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(9): Block17(
(branch0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(256, 896, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
)
(mixed_7a): Mixed_7a(
(branch0): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(256, 384, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(896, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(branch3): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(repeat_3): Sequential(
(0): Block8(
(branch0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(384, 1792, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(1): Block8(
(branch0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(384, 1792, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(2): Block8(
(branch0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(384, 1792, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(3): Block8(
(branch0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(384, 1792, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
(4): Block8(
(branch0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(384, 1792, kernel_size=(1, 1), stride=(1, 1))
(relu): ReLU()
)
)
(block8): Block8(
(branch0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(branch1): Sequential(
(0): BasicConv2d(
(conv): Conv2d(1792, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(1): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(2): BasicConv2d(
(conv): Conv2d(192, 192, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
(bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
)
(conv2d): Conv2d(384, 1792, kernel_size=(1, 1), stride=(1, 1))
)
(avgpool_1a): AdaptiveAvgPool2d(output_size=1)
(dropout): Dropout(p=0.6, inplace=False)
(last_linear): Linear(in_features=1792, out_features=512, bias=False)
(last_bn): BatchNorm1d(512, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
(logits): Linear(in_features=512, out_features=1, bias=True)
)
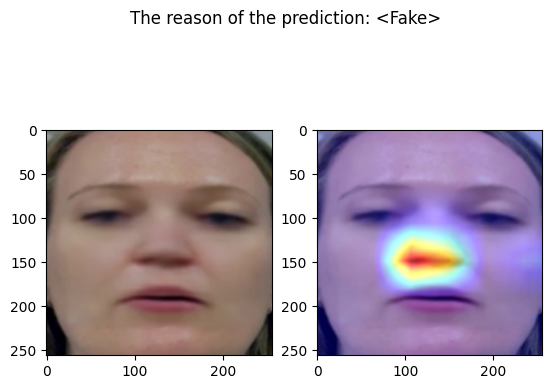
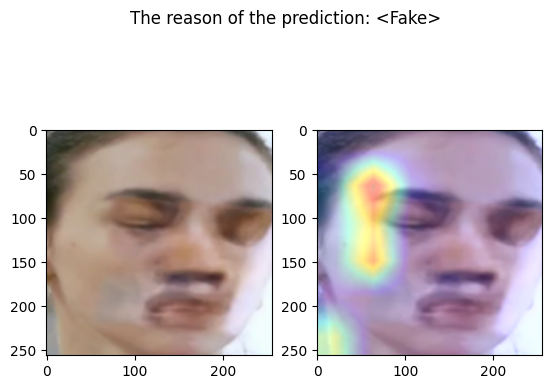
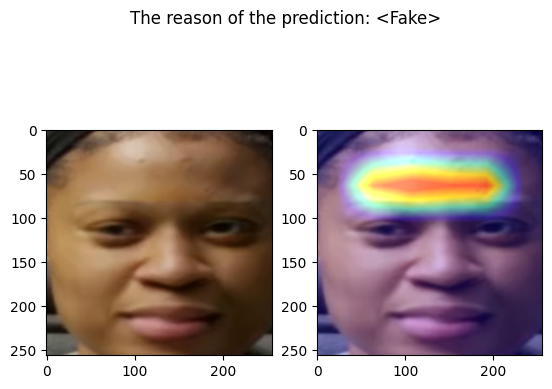
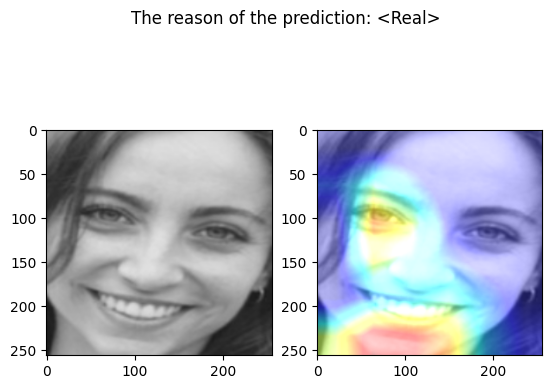
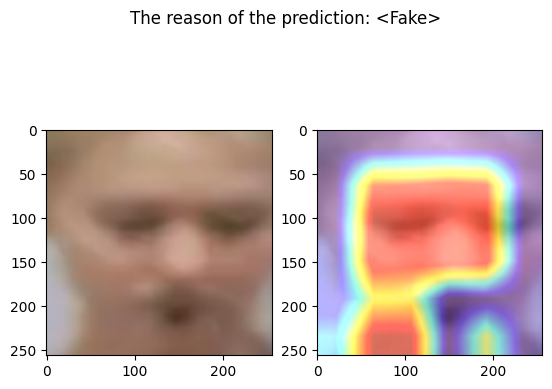
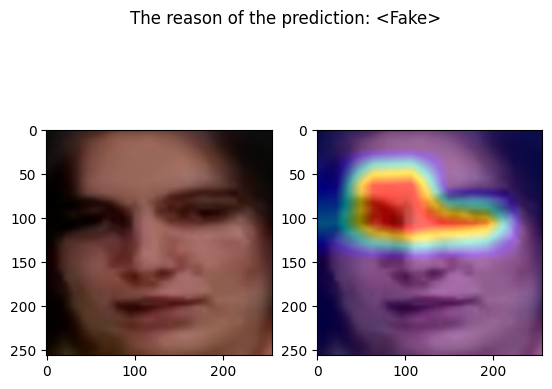
The following code define a function that takes an input image and output the corresponding prediction
def predict(input_image):
"""Predict the label of the input_image"""
face = mtcnn(input_image)
if face is None:
raise Exception("No face detected")
face = face.unsqueeze(0) # add the batch dimension
face = F.interpolate(face, size=(256, 256), mode="bilinear", align_corners=False)
# convert the face into a numpy array to be able to plot it
prev_face = face.squeeze(0).permute(1, 2, 0).cpu().detach().int().numpy()
prev_face = prev_face.astype("uint8")
face = face.to(DEVICE)
face = face.to(torch.float32)
face = face / 255.0
face_image_to_plot = face.squeeze(0).permute(1, 2, 0).cpu().detach().int().numpy()
target_layers = [model.block8.branch1[-1]]
cam = GradCAM(model=model, target_layers=target_layers)
targets = [ClassifierOutputTarget(0)]
grayscale_cam = cam(input_tensor=face, targets=targets, eigen_smooth=True)
grayscale_cam = grayscale_cam[0, :]
visualization = show_cam_on_image(face_image_to_plot, grayscale_cam, use_rgb=True)
face_with_mask = cv2.addWeighted(prev_face, 1, visualization, 0.5, 0)
with torch.no_grad():
output = torch.sigmoid(model(face).squeeze(0))
prediction = "real" if output.item() < 0.5 else "fake"
real_prediction = 1 - output.item()
fake_prediction = output.item()
confidences = {"real": real_prediction, "fake": fake_prediction}
return confidences, prev_face, face_with_mask
import glob
from PIL import Image
import matplotlib.pyplot as plt
def display_result(fname):
im = Image.open(fname)
print("=" * 80)
print(" " * 20 + fname)
print("=" * 80)
plt.imshow(im)
plt.title(fname)
plt.show()
out = predict(im)
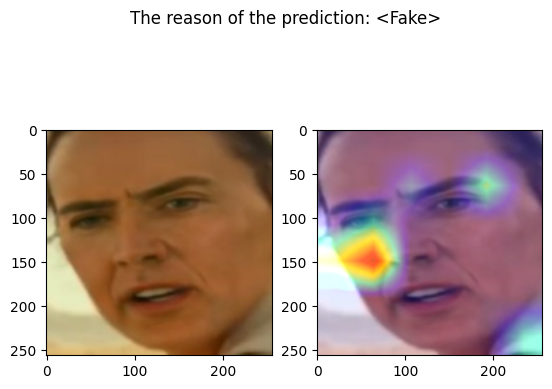
pred = "<Real>" if out[0]["real"] > 0.5 else "<Fake>"
print(f"Predicted by our model: {pred} [{out[0]}]")
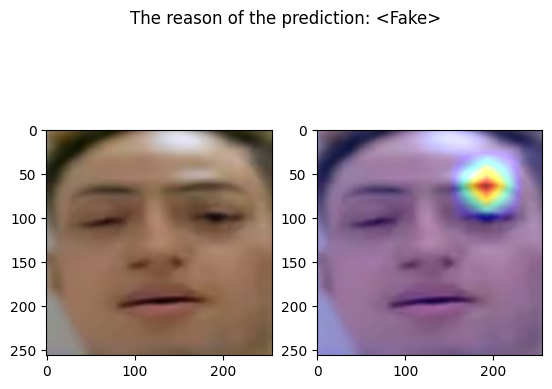
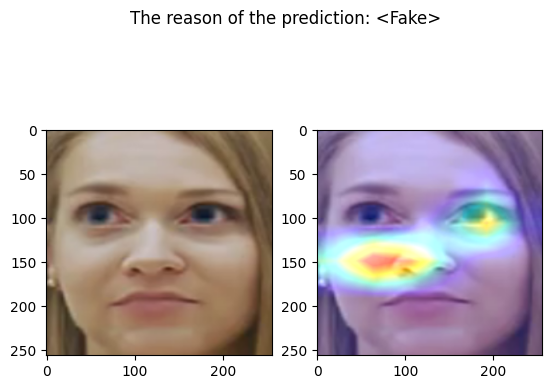
fig, axs = plt.subplots(1, 2)
fig.suptitle(f"The reason of the prediction: {pred}")
axs[0].imshow(out[1])
axs[1].imshow(out[2])
plt.show()
for fname in glob.glob("examples/*"):
display_result(fname)
================================================================================
examples/fake_frame_1.png
================================================================================

Predicted by our model: <Fake> [{'real': 0.00010454654693603516, 'fake': 0.999895453453064}]
================================================================================
examples/fake_frame_3.png
================================================================================

Predicted by our model: <Fake> [{'real': 5.233287811279297e-05, 'fake': 0.9999476671218872}]
================================================================================
examples/fake_frame_2.png
================================================================================

Predicted by our model: <Fake> [{'real': 0.00011217594146728516, 'fake': 0.9998878240585327}]
================================================================================
examples/fake_frame_6.png
================================================================================

Predicted by our model: <Fake> [{'real': 0.00018721818923950195, 'fake': 0.9998127818107605}]
================================================================================
examples/fake_frame_7.png
================================================================================

Predicted by our model: <Fake> [{'real': 0.00023192167282104492, 'fake': 0.999768078327179}]
================================================================================
examples/fake_frame_5.png
================================================================================
Predicted by our model: <Fake> [{'real': 0.00187760591506958, 'fake': 0.9981223940849304}]

================================================================================
examples/real_mercedes.jpeg
================================================================================
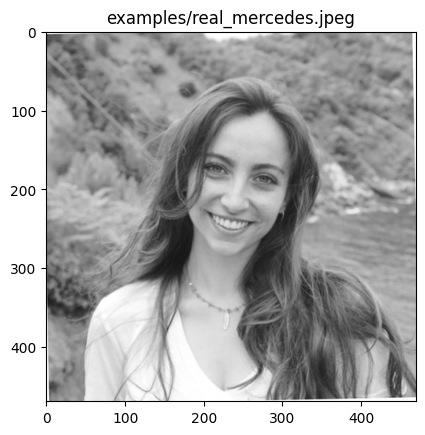
Predicted by our model: <Real> [{'real': 0.8550797253847122, 'fake': 0.14492027461528778}]
================================================================================
examples/fake_frame_4.png
================================================================================

Predicted by our model: <Fake> [{'real': 0.21064341068267822, 'fake': 0.7893565893173218}]
================================================================================
examples/real_frame_19.png
================================================================================

Predicted by our model: <Real> [{'real': 0.9999999760254799, 'fake': 2.3974520146907707e-08}]

================================================================================
examples/fake_frame_15.png
================================================================================

Predicted by our model: <Fake> [{'real': 0.001075446605682373, 'fake': 0.9989245533943176}]
================================================================================
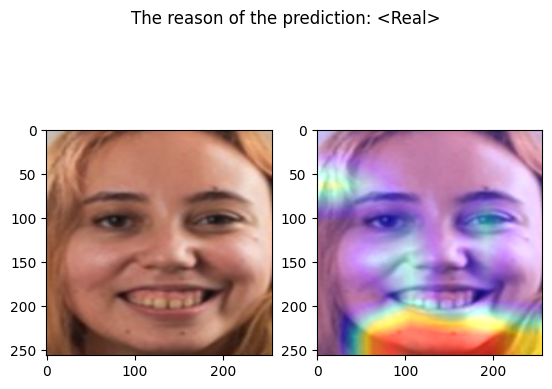
examples/real_frame_9.png
================================================================================

Predicted by our model: <Real> [{'real': 0.9999986545436741, 'fake': 1.3454563259074348e-06}]
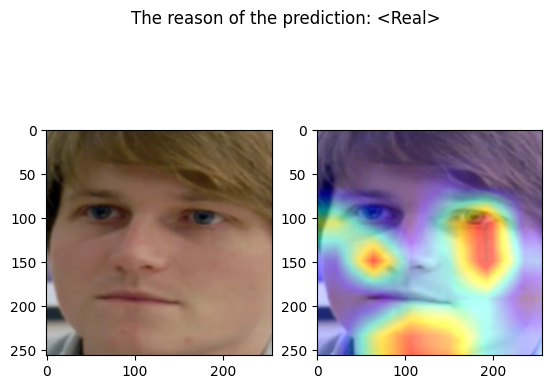
================================================================================
examples/real_lucia.jpeg
================================================================================
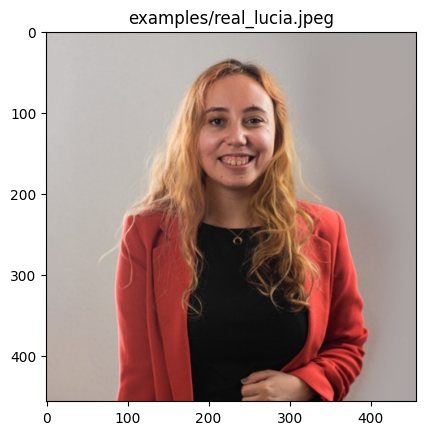
Predicted by our model: <Real> [{'real': 0.9999999977415401, 'fake': 2.2584598635688735e-09}]
================================================================================
examples/fake_frame_17.png
================================================================================

Predicted by our model: <Fake> [{'real': 2.384185791015625e-07, 'fake': 0.9999997615814209}]

================================================================================
examples/fake_frame_16.png
================================================================================

Predicted by our model: <Fake> [{'real': 0.07662761211395264, 'fake': 0.9233723878860474}]

================================================================================
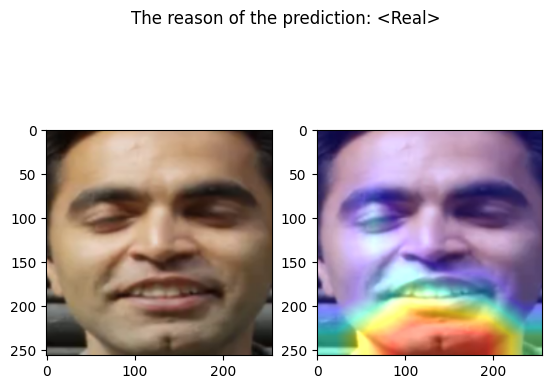
examples/real_frame_8.png
================================================================================

Predicted by our model: <Real> [{'real': 0.9999997878268374, 'fake': 2.1217316259480867e-07}]
================================================================================
examples/fake_frame_12.png
================================================================================

Predicted by our model: <Fake> [{'real': 1.4781951904296875e-05, 'fake': 0.9999852180480957}]

================================================================================
examples/fake_frame_13.png
================================================================================

Predicted by our model: <Fake> [{'real': 0.00046050548553466797, 'fake': 0.9995394945144653}]
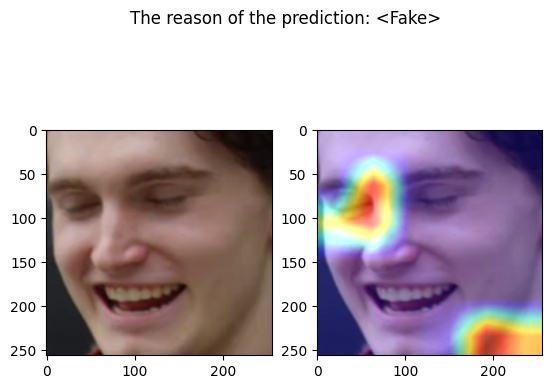
================================================================================
examples/real_frame_20.png
================================================================================

Predicted by our model: <Real> [{'real': 0.9999540159587923, 'fake': 4.598404120770283e-05}]
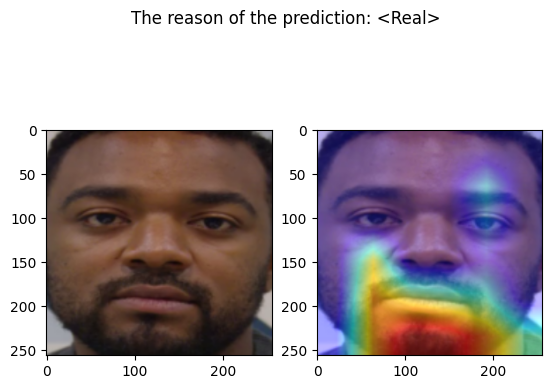
================================================================================
examples/fake_frame_11.png
================================================================================

Predicted by our model: <Fake> [{'real': 0.014934957027435303, 'fake': 0.9850650429725647}]
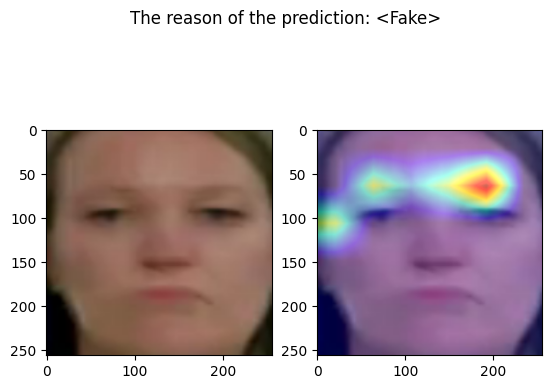
================================================================================
examples/fake_frame_10.png
================================================================================

Predicted by our model: <Fake> [{'real': 4.00543212890625e-05, 'fake': 0.9999599456787109}]

================================================================================
examples/real_frame_3.png
================================================================================

Predicted by our model: <Real> [{'real': 0.9999999934243937, 'fake': 6.575606281700175e-09}]
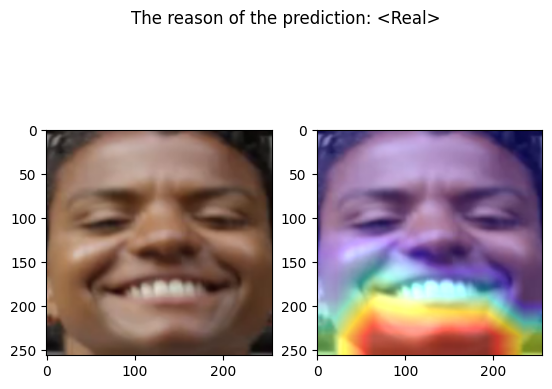
================================================================================
examples/fake_frame_20.png
================================================================================

Predicted by our model: <Fake> [{'real': 5.030632019042969e-05, 'fake': 0.9999496936798096}]

================================================================================
examples/real_frame_2.png
================================================================================

Predicted by our model: <Fake> [{'real': 0.03622013330459595, 'fake': 0.963779866695404}]
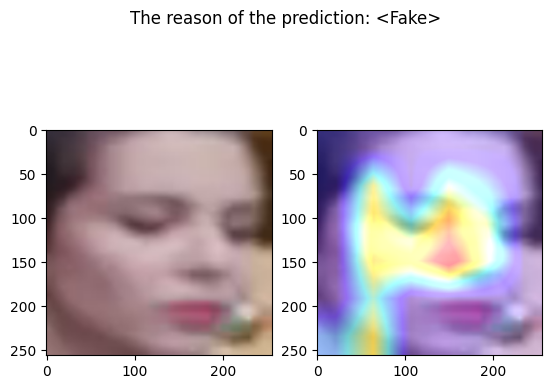
================================================================================
examples/real_frame_13.png
================================================================================

Predicted by our model: <Real> [{'real': 0.9992852220311761, 'fake': 0.0007147779688239098}]
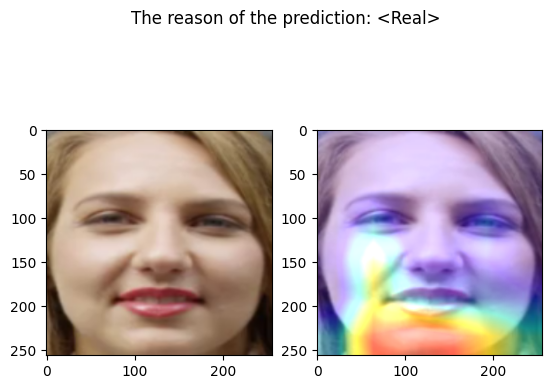
================================================================================
examples/real_frame_1.png
================================================================================

Predicted by our model: <Real> [{'real': 0.9999886736432018, 'fake': 1.1326356798235793e-05}]
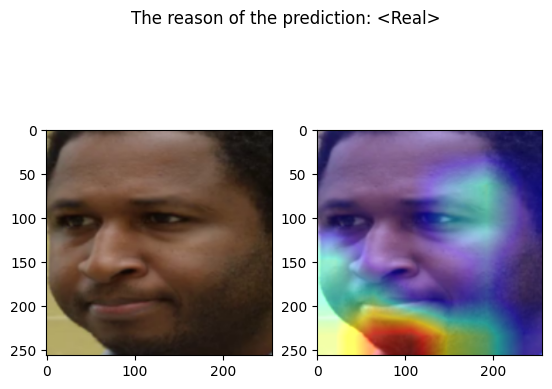
================================================================================
examples/real_frame_16.png
================================================================================

Predicted by our model: <Real> [{'real': 0.987897539511323, 'fake': 0.012102460488677025}]

================================================================================
examples/real_frame_15.png
================================================================================

Predicted by our model: <Real> [{'real': 0.5079668760299683, 'fake': 0.49203312397003174}]
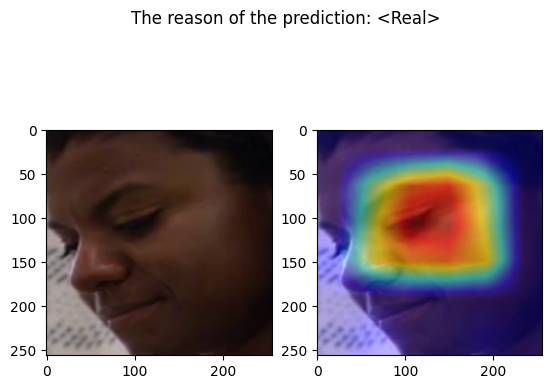
================================================================================
examples/fake_frame_19.png
================================================================================

Predicted by our model: <Fake> [{'real': 4.172325134277344e-06, 'fake': 0.9999958276748657}]

================================================================================
examples/fake_frame_9.png
================================================================================

Predicted by our model: <Fake> [{'real': 4.291534423828125e-06, 'fake': 0.9999957084655762}]

================================================================================
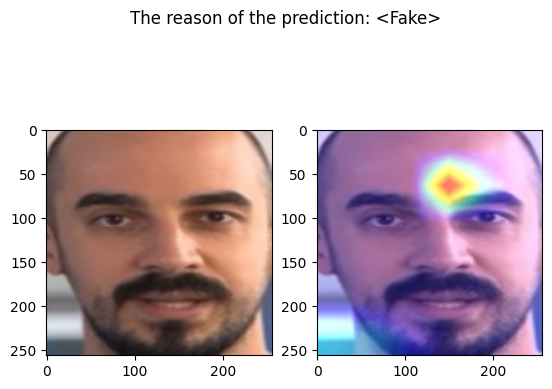
examples/fake_dot_csv.jpeg
================================================================================
Predicted by our model: <Fake> [{'real': 0.025828897953033447, 'fake': 0.9741711020469666}]
================================================================================
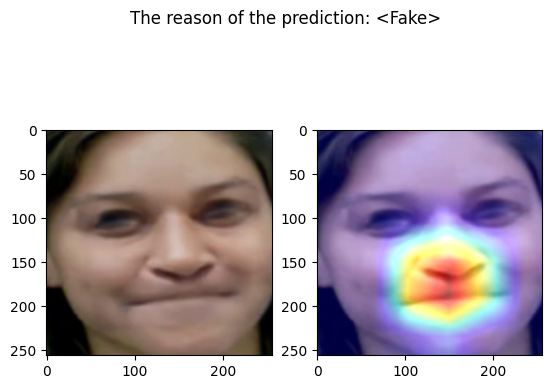
examples/fake_frame_8.png
================================================================================

Predicted by our model: <Fake> [{'real': 0.0, 'fake': 1.0}]
Let’s try some images from popular meme#
!wget https://i.ytimg.com/vi/wu-lMi1nw9s/maxresdefault.jpg -O starwar1.jpg
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
--2024-02-09 19:13:05-- https://i.ytimg.com/vi/wu-lMi1nw9s/maxresdefault.jpg
Loaded CA certificate '/etc/ssl/certs/ca-certificates.crt'
Resolving i.ytimg.com (i.ytimg.com)... 172.217.167.86, 142.250.66.246, 142.250.76.118, ...
Connecting to i.ytimg.com (i.ytimg.com)|172.217.167.86|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 74326 (73K) [image/jpeg]
Saving to: ‘starwar1.jpg’
starwar1.jpg 100%[===================>] 72.58K --.-KB/s in 0.05s
2024-02-09 19:13:06 (1.53 MB/s) - ‘starwar1.jpg’ saved [74326/74326]
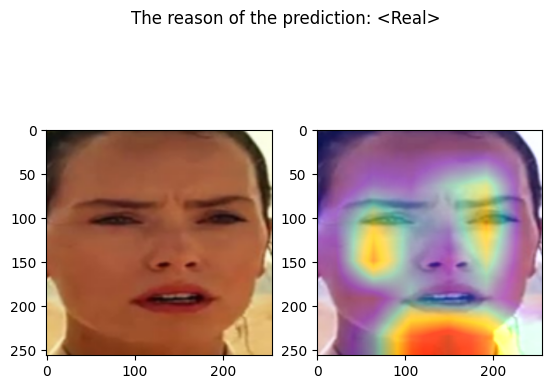
display_result("starwar1.jpg")
================================================================================
starwar1.jpg
================================================================================

Predicted by our model: <Real> [{'real': 0.9961821485776454, 'fake': 0.003817851422354579}]
Now, here comes a fake one
Starring, Nicolas Cage.
!wget https://pbs.twimg.com/media/EKi1flkXYAA5-A_?format=jpg -O starwar2.jpg
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
--2024-02-09 19:13:06-- https://pbs.twimg.com/media/EKi1flkXYAA5-A_?format=jpg
Loaded CA certificate '/etc/ssl/certs/ca-certificates.crt'
Resolving pbs.twimg.com (pbs.twimg.com)... 117.18.237.70, 2606:2800:248:1347:709:24f:182c:618
Connecting to pbs.twimg.com (pbs.twimg.com)|117.18.237.70|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 50381 (49K) [image/jpeg]
Saving to: ‘starwar2.jpg’
starwar2.jpg 100%[===================>] 49.20K --.-KB/s in 0.02s
2024-02-09 19:13:07 (2.40 MB/s) - ‘starwar2.jpg’ saved [50381/50381]
display_result("starwar2.jpg")
================================================================================
starwar2.jpg
================================================================================
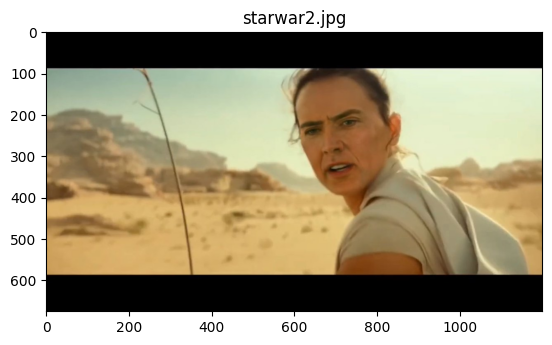
Predicted by our model: <Fake> [{'real': 0.0038504600524902344, 'fake': 0.9961495399475098}]